

Bestimmungskoeffizientenformeln, Berechnung, Interpretation, Beispiele

- 2731
- 839
- Joy Hort
Er Bestimmungskoeffizient Es handelt sich um eine Zahl zwischen 0 und 1.
Es ist auch als bekannt als Anpassungsgüte und wird mit R bezeichnet2. Um dies zu berechnen, wird der Quotient zwischen der Varianz der durch das Regressionsmodell geschätzten ŷi -Daten und der Varianz der YI -Daten, die jedem XI der Daten entsprechend entsprechend sind.
R2 = Sŷ / sy
Abbildung 1. Korrelationskoeffizient für vier Datenpaare. Quelle: f. Zapata. Wenn sich 100% der Daten in der Regressionsfunktionslinie befinden, beträgt der Bestimmungskoeffizient 1.
Im Gegenteil, wenn für einen Datensatz und eine bestimmte Anpassungsfunktion der R -Koeffizient r2 Es stellt sich heraus, dass es gleich 0 ist.5, dann kann man sagen, dass die Anpassung bei 50% zufriedenstellend oder gut ist.
In ähnlicher Weise löst das Regressionsmodell die Werte von r aus2 Weniger als 0.5 Dies zeigt an, dass sich die ausgewählte Einstellfunktion nicht zufriedenstellend an die Daten anpasst und daher erforderlich ist, um nach einer anderen Anpassungsfunktion zu suchen.
Und wann Kovarianz oder der Korrelationskoeffizient Es tendiert zu Null, dann sind die Variablen x und y aus den Daten nicht verwandt und daher r2 wird auch neigen zu Null.
[TOC]
Wie man den Bestimmungskoeffizienten berechnet?
Im vorherigen Abschnitt wurde gesagt, dass der Bestimmungskoeffizient berechnet wird, indem der Quotient zwischen den Varianzen ermittelt wird:
-Geschätzt durch die Regressionsfunktion der Variablen und
-Die yi -Variable, die jeder der XI -Variablen entspricht.
In mathematischer Form bleibt es so:
R2 = Sŷ / sy
Aus dieser Formel folgt, dass r2 repräsentiert den Varianzanteil, der durch das Regressionsmodell erklärt wird. Alternativ kann R berechnet werden2 Durch die folgende Formel, völlig äquivalent mit der vorherigen:
R2 = 1 - (sε / sy)
Wobei Sε die Varianz des Abfalls repräsentiert εi = ŷi - yi, während SY die Varianz des Datensatzes der Daten der Daten ist. Um ŷi zu bestimmen, wird die Regressionsfunktion angewendet, was bedeutet, dass ŷi = f (xi).
Es kann Ihnen dienen: Fraktionsäquivalent zu 3/5 (Lösung und Erklärung)Die Varianz des YI -Datensatzes mit I von 1 nach N wird auf diese Weise berechnet:
Sy = [σ (yi -)2 ) / (N-1)]
Und fahren Sie dann in ähnlicher Weise für Sŷ oder für Sε fort.
Illustrativer Fall
Um das Detail der Art und Weise zu zeigen, wie die Berechnung der Berechnung der Bestimmungskoeffizient Wir werden den folgenden Satz von vier Datenpaaren nehmen:
(X, y): (1, 1); (23); (3, 6) und (4, 7).
Für diesen Datensatz wird eine lineare Regressionsanpassung vorgeschlagen, die mit der Methode der quadratischen Minimum erhalten wurde:
f (x) = 2.1 x - 1
Wenn Sie diese Einstellfunktion anwenden, werden die Kollegen erhalten:
(X, ŷ): (1, 1.1); (23.2); (3, 5.3) und (4, 7.4).
Dann berechnen wir den arithmetischen Mittelwert für x und y:
= (1 + 2 + 3 + 4) / 4 = 2.5
= (1 + 3 + 6 + 7) / 4 = 4 = 4.25
Varianz Sy
Sy = [(1 - 4).25)2 + (3. 4.25)2 + (6 - 4.25)2 +.. ... .(7 - 4.25)2] / (4-1) =
= [-3.25)2+ (-1.25)2 + (1.75)2 + (2.75)2) / (3)] = 7.583
Varianz Sŷ
Sŷ = [(1.1 - 4.25)2 + (3.2 - 4.25)2 + (5.3. 4.25)2 +.. ... .(7.4 - 4.25)2] / (4-1) =
= [-3.25)2 + (-1.25)2 + (1.75)2 + (2.75)2) / (3)] = 7.35
Bestimmungskoeffizient r2
R2 = Sŷ / sy = 7.35/7.58 = 0.97
Deutung
Der Bestimmungskoeffizient für den im vorherigen Segment berücksichtigten Veranschaulichungsfall war 0.98. Das heißt, die lineare Einstellung durch die Funktion:
f (x) = 2.1x - 1
Es ist zu 98% zuverlässig, die Daten zu erklären, mit denen sie über die minimale Quadratmethode erhalten wurden.
Zusätzlich zum Bestimmungskoeffizienten gibt es die Linearer Korrelationskoeffizient oder auch als Pearson -Koeffizient bezeichnet. Dieser Koeffizient, bezeichnet als als R, Es wird durch die folgende Beziehung berechnet:
R = sxy / (sx sy)
Hier repräsentiert der Zähler die Kovarianz zwischen den Variablen x und y, während der Nenner das Produkt der Standardabweichung für die Variable x und die Standardabweichung für die Variable und die Standardabweichung ist.
Der Koeffizient von Pearson kann Werte zwischen -1 und +1 erfolgen. Wenn dieser Koeffizient zu +1 tendiert, besteht eine direkte lineare Korrelation zwischen x und y. Wenn es stattdessen tendenziell zu -1 tendiert, gibt es eine lineare Korrelation, aber wenn X wächst und abnimmt. Schließlich ist es nahe bei 0, es gibt keine Korrelation zwischen den beiden Variablen.
Kann Ihnen dienen: Gruppierte Daten: Beispiele und Übung behobenEs ist zu beachten, dass der Bestimmungskoeffizient mit dem Quadrat des Pearson -Koeffizienten zusammenfällt, nur wenn die erste auf der Grundlage einer linearen Anpassung berechnet wurde, diese Gleichheit ist jedoch für andere nichtlineare Anpassungen nicht gültig.
Beispiele
- Beispiel 1
Eine Gruppe von Schülern beabsichtigt, ein empirisches Gesetz für die Zeit eines Pendels als Funktion seiner Länge zu bestimmen. Um dieses Ziel zu erreichen, machen sie eine Reihe von Messungen, in denen sie die Zeit einer Pendelschwingung für unterschiedliche Längen messen, die die folgenden Werte erhalten:
| Länge (m) | Periode (en) |
|---|---|
| 0,1 | 0,6 |
| 0,4 | 1.31 |
| 0,7 | 1.78 |
| 1 | 1.93 |
| 1.3 | 2.19 |
| 1.6 | 2.66 |
| 1.9 | 2.77 |
| 3 | 3.62 |
Es wird gebeten, ein Datendispersionsdiagramm vorzunehmen und eine lineare Anpassung durch Regression vorzunehmen. Darüber hinaus zeigen Sie die Regressionsgleichung und ihren Bestimmungskoeffizienten.
Lösung
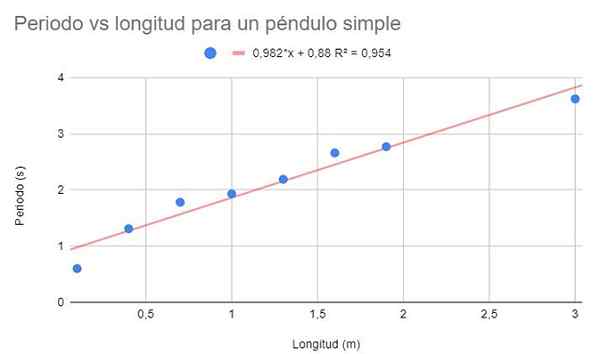 Figur 2. Grafische Lösung der Übung 1. Quelle: f. Zapata.
Figur 2. Grafische Lösung der Übung 1. Quelle: f. Zapata. Ein ziemlich hoher Bestimmungskoeffizient (95%) kann beobachtet werden, so dass die lineare Anpassung optimal ist. Wenn die Punkte jedoch zusammen beobachtet werden, scheint es, dass sie die Tendenz neigen, sich zu krümmen. Dieses Detail wird im linearen Modell nicht in Betracht gezogen.
- Beispiel 2
Machen Sie für die gleichen Daten von Beispiel 1 ein Datendispersionsdiagramm. Bei dieser Gelegenheit wird es im Gegensatz zu Beispiel 1 gebeten, eine Regressionsanpassung durch eine potenzielle Funktion vorzunehmen.
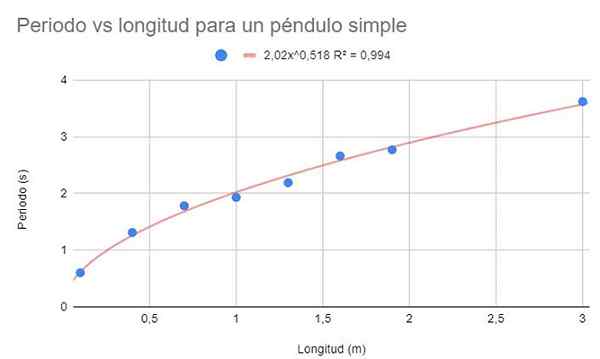 Figur 3. Grafische Lösung von Übung 2. Quelle: f. Zapata.
Figur 3. Grafische Lösung von Übung 2. Quelle: f. Zapata. Zeigen Sie auch die Einstellfunktion und ihren R -Bestimmungskoeffizienten2.
Lösung
Die potenzielle Funktion ist aus der Form f (x) = axB, wobei a und b konstant sind und durch minimale Quadratmethode bestimmt werden.
Die vorherige Abbildung zeigt die potenzielle Funktion und ihre Parameter sowie den Bestimmungskoeffizienten mit einem sehr hohen Wert von 99%. Beachten Sie, dass die Daten der Krümmung der Trendlinie folgen.
Kann Ihnen dienen: Additivprinzip- Beispiel 3
Nehmen Sie mit den gleichen Daten von Beispiel 1 und Beispiel 2 eine zweite Polynomanpassung vor. Zeigen Sie die Grafik, das Einstellungspolynom und den Bestimmungskoeffizienten r2 Korrespondent.
Lösung
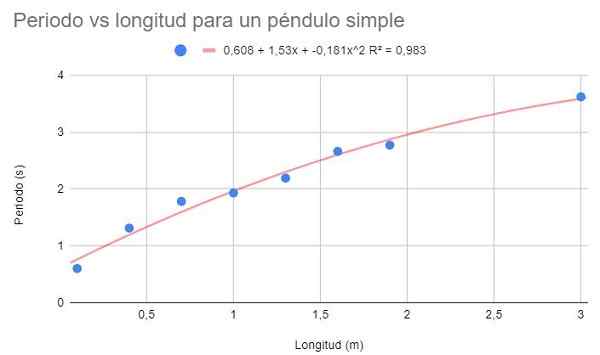 Figur 4. Grafikübung 3 Diagramm. Quelle: f. Zapata.
Figur 4. Grafikübung 3 Diagramm. Quelle: f. Zapata. Bei der Polynomanpassung zweiten Grades ist eine Trendlinie zu erkennen, die gut zur Krümmung der Daten passt. Ebenso liegt der Bestimmungskoeffizient über der linearen Einstellung und unter der potenziellen Einstellung.
Anpassungsvergleich
Von den drei gezeigten Anpassungen ist die mit einem höheren Bestimmungskoeffizienten die potenzielle Anpassung (Beispiel 2).
Die mögliche Anpassung fällt mit der physikalischen Theorie des Pendels zusammen, die, wie bekannt ist, feststellt der Schwerkraft.
Diese Art der potenziellen Anpassung hat nicht nur den höchsten Bestimmungskoeffizienten, sondern auch die Konstante der Exponenten und die Verhältnismäßigkeit übereinstimmt mit dem physischen Modell zusammen.
Schlussfolgerungen
-Die Regressionsanpassung bestimmt die Parameter der Funktion, die darauf abzielt, die Daten über die minimale Quadratmethode zu erklären. Diese Methode besteht darin, die Summe der quadratischen Differenz zwischen Wert und Anpassung und dem YI -Wert der Daten für die XI -Werte der Daten zu minimieren. Auf diese Weise werden die Parameter der Einstellfunktion bestimmt.
-Wie wir gesehen haben, ist die häufigste Anpassungsfunktion die Linie, aber nicht die einzige, da die Anpassungen auch polynomisch, potenziell, exponentiell, logarithmen und andere sein können.
-In jedem Fall hängt der Bestimmungskoeffizient von den Daten und der Art der Anpassung ab und ist ein Hinweis auf die Güte der angewendeten Anpassung.
-Schließlich gibt der Bestimmungskoeffizient den Prozentsatz der Gesamtvariabilität zwischen dem Wert und den Daten in Bezug auf den ŷ -Wert der Anpassung für den gegebenen X an.
Verweise
- González c. Allgemeine Statistiken. Erholt von: Tarwi.La Molina.Edu.Sport
- IACs. Das Aragonesen Institut für Gesundheitswissenschaften. Abgerufen von: ICS-Aragon.com
- Salazar c. und Castillo s. Grundlegende Statistiken Prinzipien. (2018). Abgerufen von: dspace.Uce.Edu.EC
- Superprof. Bestimmungskoeffizient. Erholt von: Superprof.Ist
- USAC. Beschreibender Statistikhandbuch. (2011). Erholt aus: Statistik.Maschinenbau.USAC.Edu.Gt.
- Wikipedia. Bestimmungskoeffizient. Geborgen von: ist.Wikipedia.com.
- « Tukey -Test in Was ist Meister, Bewegung gelöst
- Positionsmaßnahmen, zentrale Tendenz und Dispersion »