

Gruppierte Datenbeispiele und gelöste Übung

- 1312
- 199
- Tizian Liebich
Der Gruppierte Daten Sie sind diejenigen, die in Kategorien oder Kurse eingeteilt haben und ihre Häufigkeit als Kriterien einnehmen. Dies geschieht mit dem Zweck, die Verwaltung großer Datenmengen zu vereinfachen und deren Trends festzulegen.
Einmal in diesen Klassen für ihre Frequenzen organisiert, bilden die Daten a Häufigkeitsverteilung, aus welcher Nützlichkeitsinformationen durch seine Eigenschaften extrahiert werden.
Abbildung 1. Mit den gruppierten Daten können Sie Grafiken erstellen und statistische Parameter berechnen, die Trends beschreiben. Quelle: Pixabay. Als nächstes sehen wir ein einfaches Beispiel für gruppierte Daten:
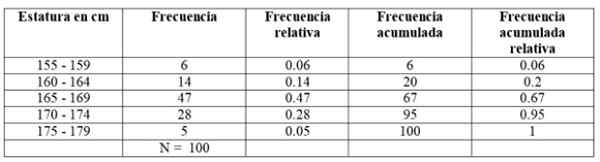
Angenommen, die Statur von 100 weiblichen Studenten, die aus allen grundlegenden Physikkursen einer Universität ausgewählt wurden, wird gemessen und die folgenden Ergebnisse werden erzielt:

Die erhaltenen Ergebnisse wurden in 5 Klassen unterteilt, die in der linken Spalte erscheinen.
Die erste Klasse zwischen 155 und 159 cm hat 6 Schüler, die zweite Klasse 160 - 164 cm hat 14 Schüler, die dritte Klasse von 165 bis 169 cm ist die mit der größten Anzahl von Mitgliedern: 47. Folgen Sie dann der Klasse von 170-174 cm mit 28 Schülern und schließlich der von 175 bis 179 cm mit nur 5.
Die Anzahl der Mitglieder jeder Klasse ist genau die Frequenz entweder Absolutes Fleiß Und indem sie alle hinzufügen, werden die Gesamtdaten erhalten, was in diesem Beispiel 100 ist.
[TOC]
Frequenzverteilungsmerkmale
Frequenz
Wie wir gesehen haben, ist die Frequenz die Häufigkeit, mit der eine Tatsache wiederholt wird. Und um die Berechnungen der Verteilungseigenschaften wie Durchschnitt und Varianz zu erleichtern, werden die folgenden Mengen definiert:
-Angesammelte Frequenz: Es wird erhalten, indem die Frequenz einer Klasse mit der vorderen akkumulierten Frequenz addiert wird. Die erste der Frequenzen fällt mit dem des fraglichen Intervalls zusammen, und die letzte ist die Gesamtzahl der Daten.
-Relative Frequenz: Es wird berechnet, indem die absolute Häufigkeit jeder Klasse durch die Gesamtzahl der Daten geteilt wird. Und wenn Sie sich mit 100 multiplizieren.
Kann Ihnen dienen: Vektorfunktionen-Angesammelte relative Frequenz: Es ist die Summe der relativen Frequenzen jeder Klasse mit den vorherigen akkumulierten. Der letzte der angesammelten relativen Frequenzen muss gleich 1 sein.
Für unser Beispiel sind die Frequenzen wie folgt:
Grenzen
Die extremen Werte jeder Klasse oder jedes Intervalls werden genannt Klassengrenzen. Wie wir sehen können, hat jede Klasse eine Untergrenze und eine größere. Zum Beispiel hat die erste Klasse der Studie über die Staturen eine Grenze von weniger als 155 cm und einer mehr als 159 cm.
Dieses Beispiel hat Grenzen, die klar definiert sind, es ist jedoch möglich.
Grenzen
Höhe ist eine kontinuierliche Variable, sodass berücksichtigt werden kann, dass die erste Klasse tatsächlich in 154 beginnt.5 cm, da durch Runden dieses Wertes auf die nächste Ganzzahl abgerundet wird, wird 155 cm erhalten.
Diese Klasse deckt alle Werte bis zu 159 ab.5 cm, denn aus diesem Grund sind die Staturen auf 160 abgerundet.0 cm. Eine Statur von 159.7 cm gehört bereits zur nächsten Klasse.
Die wirklichen Klassengrenzen dieses Beispiels sind in CM:
- 154.5 - 159.5
- 159.5 - 164.5
- 164.5 - 169.5
- 169.5 - 174.5
- 174.5 - 179.5
Amplitude
Die Breite einer Klasse wird durch Subtrahieren der Grenzen erhalten. Für das erste Intervall unser Beispiel haben Sie 159.5 - 154.5 cm = 5 cm.
Der Leser kann überprüfen, dass die Amplitude für die anderen Intervalle des Beispiels auch aus 5 cm result. Es ist jedoch bemerkenswert, dass Verteilungen mit Intervallen verschiedener Amplitude erstellt werden können.
Es kann Ihnen dienen: Regel T: Merkmale, damit es Beispiele istKlassenmarke
Es ist der mittlere Punkt des Intervalls und wird durch den Durchschnitt zwischen der Obergrenze und der unteren Grenze erhalten.
Für unser Beispiel ist die erste Klasse Marke (155 + 159)/2 = 157 cm. Der Leser kann überprüfen, ob die verbleibenden Klassenmarken: 162, 167, 172 und 177 cm sind.
Die Bestimmung von Klassenmarken ist wichtig, da sie notwendig sind, um den arithmetischen Mittelwert und die Varianz der Verteilung zu finden.
Messungen der zentralen Tendenz und Dispersion für gruppierte Daten
Die am häufigsten verwendeten zentralen Tendenzmaßnahmen sind durchschnittlich, median und modisch und beschreiben genau die Tendenz der Daten, die um einen bestimmten zentralen Wert gruppiert werden, genau.
Halb
Es ist eine der wichtigsten zentralen Tendenzmaßnahmen. In den gruppierten Daten kann der arithmetische Mittelwert unter Verwendung der Formel berechnet werden:

-X ist der Durchschnitt
-FYo ist die Häufigkeit der Klasse
-MYo Es ist die Klassenmarke
-G ist die Anzahl der Klassen
-n ist die Gesamtzahl der Daten
Median
Für den Median muss man das Intervall identifizieren, in dem sich die Beobachtung n/2 befindet. In unserem Beispiel ist diese Beobachtung die Nummer 50, da es insgesamt 100 Daten gibt. Diese Beobachtung liegt im Intervall 165-169 cm.
Dann müssen Sie interpolieren, um den numerischen Wert zu finden, der dieser Beobachtung entspricht, für die die Formel verwendet wird:
c)
Wo:
-C = Intervallbreite, in der sich der Median befindet
-BM = Der untere Rand des Intervalls, zu dem der Median gehört
-FM = Menge der Beobachtungen, die im mittleren Intervall enthalten sind
-N/2 = die Hälfte der Gesamtdaten
-FBM = Gesamtzahl der Beobachtungen vor dem mittleren Intervall
Mode
Für die Mode wird die modale Klasse identifiziert, die die meisten Beobachtungen enthält, deren Klassenmarke bekannt ist.
Kann dir dienen: hexagonale PyramideVarianz und Standardabweichung
Varianz und Standardabweichung sind Dispersionsmaßnahmen. Wenn wir die Abweichung mit s bezeichnen2 Und zur Standardabweichung, die die Quadratwurzel der Varianz als S ist, für gruppierte Daten haben wir jeweils:
^2n-1)
UND
^2n-1)
Übung gelöst
Berechnen Sie die Werte von:
a) Durchschnitt
b) mittel
c) Mode
d) Varianz und Standardabweichung.
 Figur 2. Wenn es um viele Werte geht, z. Quelle: Pixabay.
Figur 2. Wenn es um viele Werte geht, z. Quelle: Pixabay. Lösung für
Erstellen wir die folgende Tabelle, um die Berechnungen zu erleichtern:
 Durch den Ausdruck für die oben gruppierte durchschnittliche Gruppe:
Durch den Ausdruck für die oben gruppierte durchschnittliche Gruppe:
Werte ersetzen und die Summe direkt ausführen:
X = (6 x 157 + 14 x 162 + 47 x 167 + 28 x 172+ 5 x 177) /100 cm =
= 167.6 cm
Lösung b
Das Intervall, zu dem der Median gehört.
Identifizieren wir jeden dieser Werte im Beispiel mit Hilfe von Tabelle 2:
C = 5 cm (siehe Amplitudenabschnitt)
BM = 164.5 cm
FM = 47
N/2 = 100/2 = 50
FBM = 20
Ersetzen in der Formel:
5\:&space;cm=&space;167.7\:&space;cm) Lösung c
Lösung c
Das in den meisten Beobachtungen enthaltene Intervall beträgt 165-169 cm, dessen Klassenmarke 167 cm beträgt.
Lösung d
Wir erweitern die vorherige Tabelle, indem wir zwei zusätzliche Spalten hinzufügen:
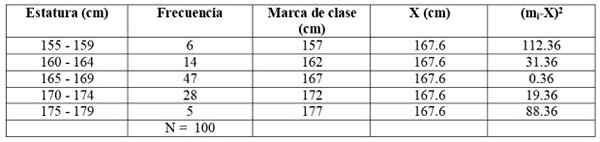
Wir wenden die Formel an:
Und wir entwickeln die Summe:
S2 = (6 x 112.36 + 14 x 31.36 + 47 x 0.36 + 28 x 19.36 + 5 x 88.36) / 99 = = 21.35 cm2
Deshalb:
S = √21.35 cm2 = 4.6 cm
Verweise
- Berenson, m. 1985. Statistiken für Verwaltung und Wirtschaftswissenschaften. Inter -American s.ZU.
- Canavos, g. 1988. Wahrscheinlichkeit und Statistik: Anwendungen und Methoden. McGraw Hill.
- Devore, j. 2012. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. 8. Auflage. Cengage.
- Levin, r. 1988. Statistiken für Administratoren. 2. Auflage. Prentice Hall.
- Spiegel, m. 2009. Statistiken. Schaum -Serie. 4 Ta. Auflage. McGraw Hill.
- Walpole, r. 2007. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. Pearson.
- « U -Test von Mann - Whitney Was ist und wenn gilt, Ausführung, Beispiel
- Chi-Quadrat-Verteilung (χ²), wie es berechnet wird, Beispiele »