

Verteilung F Eigenschaften und Übungen gelöst
- 3134
- 509
- Timo Rabenstein
Der Verteilung f o Die Verteilung der Fisher-Snedecor wird verwendet, um die Abweichungen von zwei verschiedenen oder unabhängigen Populationen zu vergleichen, von denen jeweils einer Normalverteilung folgt.
Die Verteilung, die der Varianz einer Reihe von Proben einer einzelnen normalen Population folgt, ist die JI-Quadratverteilung (Χ2) des Grades N-1, wenn jede der Proben des Satzes n Elemente hat.
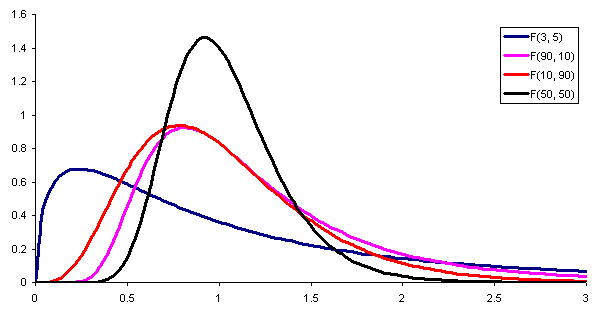
Abbildung 1. Hier ist die Wahrscheinlichkeitsdichte der Verteilung F mit unterschiedlichen Parametern (oder Grad der Freiheit) von Zähler und Nenner. Quelle: Wikimedia Commons. Um die Abweichungen von zwei verschiedenen Populationen zu vergleichen, muss a definiert werden statistisch, Das heißt, eine zufällige Hilfsvariable, die ermöglicht, zu erkennen, ob beide Populationen die gleiche Varianz haben oder nicht.
Diese Hilfsvariable kann direkt der Quotient der Stichprobenvarianzen jeder Population sein. In diesem Fall wird gezeigt, dass beide Populationen ähnliche Abweichungen haben, wenn der Quotient nahe an der Einheit liegt.
[TOC]
Die Statistik von und seine theoretische Verteilung
Die von Ronald Fisher (1890 - 1962) vorgeschlagene zufällige Variable oder statistischer F wird häufiger verwendet, um die Abweichungen von zwei Populationen zu vergleichen und wie folgt definiert:
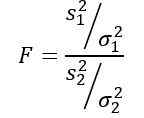
S sein2 Die Stichprobenvarianz und σ2 Die Populationsvarianz. Um jede der beiden Bevölkerungsgruppen zu unterscheiden, werden Abonnements 1 und 2 jeweils verwendet.
Es ist bekannt, dass die JI-Quadratverteilung mit (n-1) Freiheitsgraden diejenige ist, die der nachstehend definierten Hilfsvariablen (oder statistischer) folgt:
X2 = (N-1) s2 / σ2.
Daher folgt die Statistik F einer theoretischen Verteilung, die durch die folgende Formel angegeben ist:
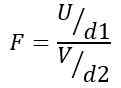
Sein ODER Die Ji-Quadrat-Verteilung mit D1 = N1 - 1 Freiheitsgrade für die Bevölkerung 1 und V Die Ji-Quadrat-Verteilung mit D2 = N2 - 1 Freiheitsgrade für die Bevölkerung 2.
Kann Ihnen dienen: VektoralgebraDas auf diese Weise definierte Verhältnis ist eine neue Wahrscheinlichkeitsverteilung, bekannt als Verteilung f mit D1 Freiheitsgrade im Zähler und D2 Freiheitsgrade im Nenner.
Durchschnitt, Mode und Varianz der Verteilung f f
Halb
Die durchschnittliche Verteilung F wird wie folgt berechnet:
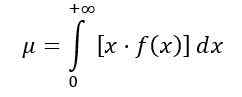
F (x) die Wahrscheinlichkeitsdichte der Verteilung F, die in Abbildung 1 für mehrere Parameter- oder Freiheitsgrade dargestellt ist.
Sie können die Wahrscheinlichkeitsdichte F (x) in Abhängigkeit von der γ -Funktion (Gamma -Funktion) schreiben:
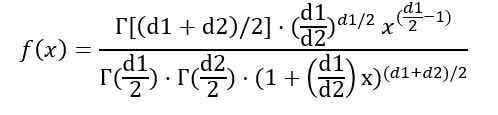
Sobald das zuvor angegebene Integral angegeben ist, wird der Durchschnitt der Verteilung F mit Freiheitsgraden (D1, D2) lautet: IS: IS: IS:::
μ = D2 / (D2 - 2) mit D2> 2
Wo es zeigt, dass der Durchschnitt merkwürdigerweise nicht von den Freiheitsgraden des Zählers abhängt.
Mode
Andererseits hängt die Mode von D1 und D2 ab und wird gegeben durch:
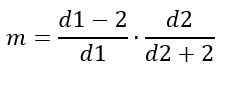
Für d1> 2.
Varianz der Verteilung f
Die Varianz σ2 der Verteilung f wird aus dem Integral berechnet:
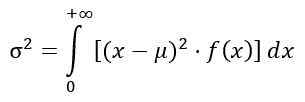
Erhalten:
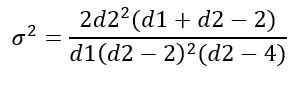
Verteilungsmanagement f
Wie andere kontinuierliche Wahrscheinlichkeitsverteilungen, die komplizierte Funktionen beinhalten.
Verteilungstabellen f
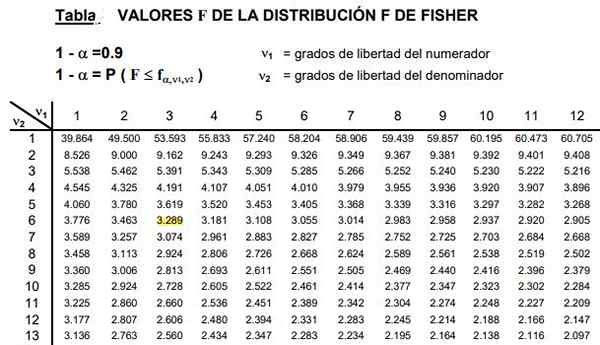 Figur 2. Es wird ein Teil der F -Verteilungstabelle gezeigt, die normalerweise sehr umfangreich sind, da eine breite Kombination möglicher Freiheitsgrade D1 und D2 vorhanden ist.
Figur 2. Es wird ein Teil der F -Verteilungstabelle gezeigt, die normalerweise sehr umfangreich sind, da eine breite Kombination möglicher Freiheitsgrade D1 und D2 vorhanden ist. Die Tabellen betreffen die beiden Parameter oder Grad der Verteilung der Verteilung F, die Spalte zeigt den Grad der Zähler und die Reihe des Grads der Freiheit des Nenners an.
Kann Ihnen dienen: Ungleichheit des Dreiecks: Demonstration, Beispiele, gelöste ÜbungenAbbildung 2 zeigt einen Abschnitt der F -Verteilungstabelle für den Fall von a Signifikanzniveau 10%, das ist α = 0,1. Der Wert von f wird hervorgehoben, wenn D1 = 3 und D2 = 6 mit Vertrauensniveau 1- α = 0,9 Das sind 90%.
Software für die Verteilung f
Was die Software betrifft, die die Verteilung f verwaltet, gibt es eine große Vielfalt, aus den Tabellenkalkulationen als Excel Sogar spezialisierte Pakete wie Minitab, SPSS Und R Um einige der bekanntesten zu nennen.
Es ist zu beachten, dass Geometrie- und Mathematiksoftware GeogeBra Es verfügt über ein statistisches Instrument, das die Hauptverteilungen enthält, einschließlich Verteilung F. Abbildung 3 zeigt die Verteilung F für Fall D1 = 3 und D2 = 6 Vertrauensniveau 90%.
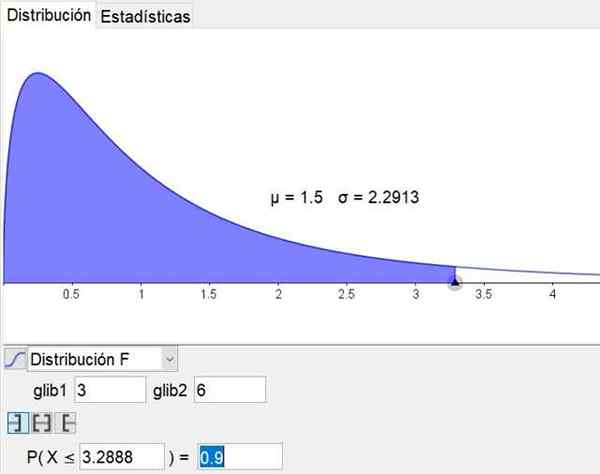 Figur 3. Die Verteilung F ist für Fall D1 = 3 und D2 = 6 mit 90%-Konfidenzniveau angezeigt, das durch das statistische Werkzeug GeogeBra erhalten wird. Quelle: Geogebra.Org
Figur 3. Die Verteilung F ist für Fall D1 = 3 und D2 = 6 mit 90%-Konfidenzniveau angezeigt, das durch das statistische Werkzeug GeogeBra erhalten wird. Quelle: Geogebra.Org Gelöste Übungen
Übung 1
Betrachten Sie zwei Proben von Populationen, die die gleiche Populationsvarianz aufweisen. Wenn Probe 1 Größe N1 = 5 ist und Probe 2 Größe N2 = 10 ist, bestimmen Sie die theoretische Wahrscheinlichkeit, dass das Verhältnis seiner jeweiligen Varianzen kleiner oder gleich 2 ist.
Lösung
Es sollte daran erinnert werden, dass die Statistik f definiert ist als:
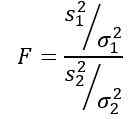
Es wird uns jedoch gesagt, dass Bevölkerungsvarianzen gleich sind, daher gilt sie für diese Übung:
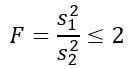
Da Sie die theoretische Wahrscheinlichkeit wissen möchten, dass dieses Verhältnis von Stichprobenvarianzen kleiner oder gleich 2 ist, müssen wir die Fläche unter der Verteilung F zwischen 0 und 2 kennen, was durch Tabellen oder Software erhalten werden kann. Dazu muss berücksichtigt werden (4, 9).
Es kann Ihnen dienen: Kraftreihe: Beispiele und ÜbungenDurch Verwendung des statistischen Instruments von GeogeBra Es wurde festgestellt, dass dieser Bereich 0 ist.82, daher wird der Schluss gezogen, dass die Wahrscheinlichkeit, dass das Verhältnis von Stichprobenvarianzen weniger als oder gleich 2 beträgt, 82% beträgt.
Übung 2
Es gibt zwei Herstellungsprozesse für dünne Bleche. Die Variabilität der Dicke muss so weit wie möglich sein. 21 Proben jedes Prozesses werden entnommen. Die Prozessprobe hat eine Standardabweichung von 1,96 Mikrometer, während die von Prozess B eine Standardabweichung von 2,13 Mikrometern hat. Welcher der Prozesse hat eine geringere Variabilität?? Verwenden Sie einen Ablehnungsniveau von 5%.
Lösung
Die Daten sind wie folgt: SB = 2,13 mit NB = 21; SA = 1,96 mit Na = 21. Dies bedeutet, dass Sie mit einer Verteilung F von (20, 20) Freiheitsgraden arbeiten müssen.
Die Nullhypothese impliziert, dass die Populationsvarianz beider Prozesse identisch ist, dh σa^2 / σb^2 = 1. Die alternative Hypothese würde unterschiedliche Bevölkerungsvarianzen implizieren.
Unter der Annahme identischer Bevölkerungsvarianzen ist die Statistik F berechnet als: fc = (sb/sa)^2 definiert.
Da das Abstoßungsniveau als α = 0,05 angenommen wurde, dann α/2 = 0,025
Die Verteilung f (0.025; 20,20) = 0,406, während f (0).975; 20,20) = 2,46.
Daher gilt die Nullhypothese, wenn der berechnete F entspricht: 0,406 ≤ FC ≤ 2,46. Andernfalls wird die Nullhypothese abgelehnt.
Als fc = (2,13/1,96)^2 = 1,18 wird der Schluss gezogen, dass sich die FC -Statistik im Akzeptanzbereich der Nullhypothese mit einer Gewissheit von 95% befindet. Mit anderen Worten mit einer Gewissheit von 95% beide Herstellungsprozesse haben die gleiche Bevölkerungsvarianz.
Verweise
- F Test für Unabhängigkeit. Erholt von: Saylordotorg.Github.Io.
- Med Welle. Statistiken für Gesundheitswissenschaften angewendet: Test f. Erholt von: medwave.Cl.
- Wahrscheinlichkeiten und Statistiken. Verteilung f. Abgerufen von: Wahrscheinlichkeiten undes.com.
- Triola, m. 2012. Elementarstatistik. 11. Auflage. Addison Wesley.
- Unam. Verteilung f. Erholt von: Beratung.Cuautitlan2.Unam.mx.
- Wikipedia. Verteilung f. Geborgen von: ist.Wikipedia.com