

Stichprobenfehlerformeln und Gleichungen, Berechnung, Beispiele
- 4413
- 1128
- Lewis Holzner
Er Stichprobenfehler entweder Beispielfehler In Statistiken ist es die Differenz zwischen dem Durchschnittswert einer Stichprobe in Bezug auf den Durchschnittswert der Gesamtbevölkerung. Um die Idee zu veranschaulichen, stellen wir uns vor, die Gesamtbevölkerung einer Stadt beträgt eine Million.
Die durchschnittliche Größe, die aus der Stichprobe erfolgt. Diese Differenz zwischen dem Durchschnittswert der Stichprobe und dem der Gesamtpopulation ist der Stichprobenfehler.
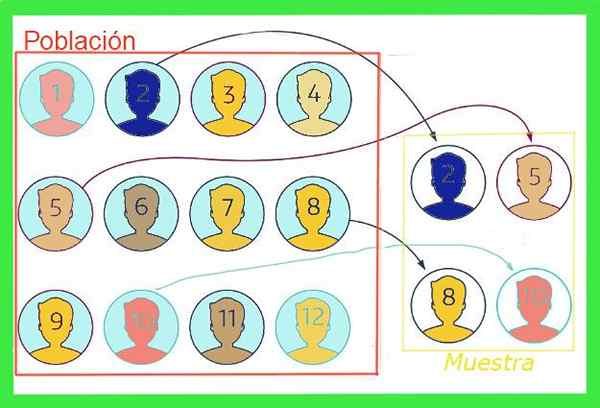
Abbildung 1. Da die Stichprobe eine Untergruppe der Gesamtpopulation ist, hat der Durchschnitt der Stichprobe eine Fehlerquote. Quelle: f. Zapata. Im Allgemeinen ist der Durchschnittswert der Gesamtbevölkerung unbekannt, es gibt jedoch Techniken, um solche Fehler und Formeln zu reduzieren, um die abzuschätzen Beispielfehlerrand Das wird in diesem Artikel ausgestellt.
[TOC]
Formeln und Gleichungen
Lassen Sie uns für den Fall, dass Sie den Durchschnittswert eines bestimmten messbaren Merkmals kennenlernen möchten X In einer Größe der Größe N, aber wie N Es ist eine große Anzahl, die Gesamtbevölkerung zu untersuchen, daher nehmen wir eine Aleatone Probe von Größe N<
Der Durchschnittswert der Stichprobe wird durch den Durchschnittswert der Gesamtbevölkerung für den griechischen Buchstaben bezeichnet μ (Es liest Mu oder miu).
Angenommen, sie werden genommen M Gesamtpopulationsproben N, Ganz gleich groß N Mit Durchschnittswerten
Diese Durchschnittswerte sind nicht identisch miteinander und alle rund um den durchschnittlichen Bevölkerungswert liegen μ. Er Stichprobenfehlerrand e Gibt die erwartete Trennung der Durchschnittswerte in Bezug auf die an Durchschnittlicher Bevölkerungswert μ Innerhalb eines bestimmten Prozentsatzes genannt die Vertrauensniveau γ (Gamma).
Kann Ihnen dienen: Additive InverseEr Standardfehlerrand ε der Größenprobe N Ist:
ε = σ/√n
Wo σ ist die Standardabweichung (Die Quadratwurzel der Varianz), die durch die folgende Formel berechnet wird:
σ = √ [(x -)2/(N - 1)]
Die Bedeutung von Standardfehlerrand ε ist das Folgende:
Er Mittelwert erhalten durch die Größenprobe N wird im Intervall verstanden ( - ε, + ε) mit einem Vertrauensniveau 68,3%.
So berechnen Sie den Stichprobenfehler
Im vorherigen Abschnitt wurde die Formel gegeben, um die zu finden Fehlerbereich Standard einer Stichprobe von n, wobei das Standardwort angibt, dass es sich um eine Fehlerquote mit 68% Vertrauen handelt.
Dies zeigt an, dass wenn viele Proben derselben Größe entnommen wurden N, 68% von ihnen geben Durchschnittswerte im Bereich an [ - ε, + ε].
Es gibt eine einfache Regel, genannt die Regel 68-95-99.7 Das ermöglicht es uns, den Rand von zu finden Beispielfehler e Für das Vertrauen der Ebene von 68%, 95% Und 99,7% Einfach, da dieser Rand 1indern istε, 2bungε und 300ε bzw.
Für ein Vertrauensniveau γ
Wenn er Vertrauensniveau γ Es ist keiner der oben genannten, daher ist der Stichprobenfehler die Standardabweichung σ multipliziert mit dem Faktor Zγ, welches durch das folgende Verfahren erhalten wird:
1.- Zuerst die Signifikanzniveau α das berechnet wird Vertrauensniveau γ Durch die folgende Beziehung: α = 1 - γ
Kann Ihnen dienen: Bayes Theorem2.- Dann müssen Sie den Wert 1 berechnen - α/2 = (1 + γ)/2, die der normalen Frequenz zwischen -∞ und entspricht Zγ, In einer normalen oder Gaußschen Verteilung typisiert F (z), deren Definition in Abbildung 2 ersichtlich ist.
3.- Die Gleichung wird gelöst F (zγ) = 1 - α/2 Durch die Normalverteilungstabellen (akkumuliert) F, o über eine Computeranwendung, die die typische inverse Gaußsche Funktion hat F-1.
Im letzteren Fall haben Sie:
Zγ = g-1(1 - α/2).
4.- Schließlich wird diese Formel für Stichprobenfehler mit einer Zuverlässigkeitsniveau angewendet γ:
E = zγ⋅(σ/√n)
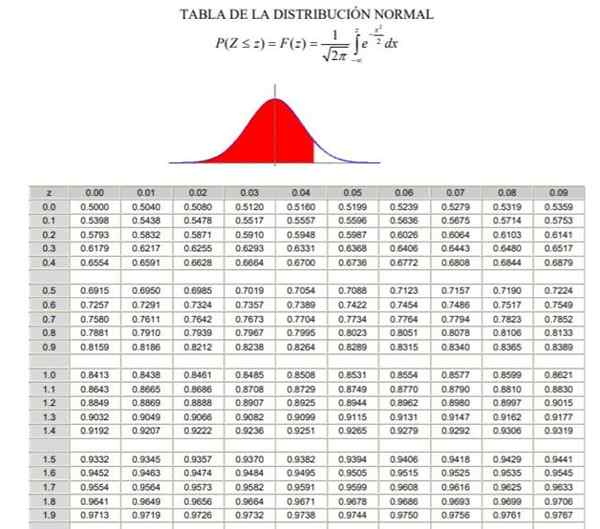 Figur 2. Normalverteilungstabelle. Quelle: Wikimedia Commons.
Figur 2. Normalverteilungstabelle. Quelle: Wikimedia Commons. Beispiele
- Beispiel 1
Berechne das Standardfehlerrand Im durchschnittlichen Gewicht einer Stichprobe von 100 Neugeborenen. Die Berechnung des durchschnittlichen Gewichts betrug = 3.100 kg mit einer Standardabweichung σ = 1.500 kg.
Lösung
Er Standardfehlerrand Ist ε = σ/√n = (1.500 kg)/√100 = 0,15 kg. Dies bedeutet, dass mit diesen Daten geschlossen werden kann, dass das Gewicht von 68% der Neugeborenen zwischen 2.950 kg und 3 liegt.25 kg.
- Beispiel 2
Bestimmen der Rand des Stichprobenfehlers und und der Gewichtsbereich von 100 Neugeborenen mit einem Konfidenzniveau von 95%, wenn das durchschnittliche Gewicht 3.100 kg mit Standardabweichung beträgt σ = 1.500 kg.
Lösung
Wenn der Regel 68; 95; 99.7 → 1 Planungε; 2bungε; 3bungε, Du hast:
E = 2offe = 2 Märed 0,15 kg = 0,30 kg
Mit anderen Worten, 95% der Neugeborenen werden Pesos zwischen 2.800 kg und 3.400 kg haben.
- Beispiel 3
Bestimmen Sie den Pesos -Bereich von Neugeborenen von Beispiel 1 mit einer Vertrauensspanne von 99,7%.
Kann Ihnen dienen: Rhomboid: Eigenschaften, wie man den Umfang und den Bereich herausnimmtLösung
Der Stichprobenfehler mit 99,7% Vertrauen ist 3 σ/√n, das für unser Beispiel ist e = 3 *0,15 kg = 0,45 kg. Von hier aus wird gefolgert, dass 99,7% der Neugeborenen Pesos zwischen 2.650 kg und 3.550 kg haben werden.
- Beispiel 4
Bestimmen Sie den Faktor Zγ Für ein Zuverlässigkeit von 75%. Bestimmen Sie die Abtastungsrand mit dieser Zuverlässigkeitsniveau für den in Beispiel 1 angesprochenen Fall.
Lösung
Er Vertrauensniveau Ist γ = 75% = 0,75, die sich auf die beziehen Signifikanzniveau α durch die Beziehung γ= (1 - α), so dass das Signifikanzniveau ist α = 1 - 0,75 = 0,25.
Dies bedeutet, dass die akkumulierte normale Wahrscheinlichkeit zwischen -∞ und Zγ Ist:
P (z ≤ Zγ ) = 1 - 0,125 = 0,875
Was entspricht einem Wert Zγ von 1.1503, wie in Abbildung 3 gezeigt.
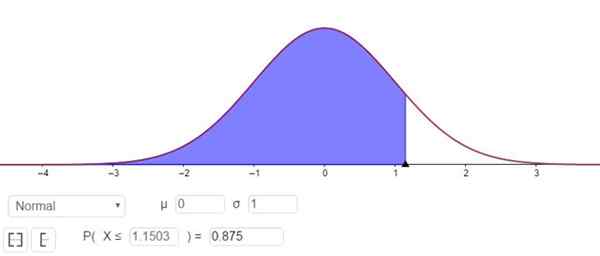 Figur 3. Bestimmung des Zγ -Faktors, der einem Konfidenzniveau von 75% entspricht. Quelle: f. Zapata durch GeoGebra.
Figur 3. Bestimmung des Zγ -Faktors, der einem Konfidenzniveau von 75% entspricht. Quelle: f. Zapata durch GeoGebra. Mit anderen Worten, der Stichprobenfehler ist E = zγ⋅(σ/√n)= 1.15⋅(σ/√n).
Wenn Sie auf Beispiel 1 angewendet werden, gibt es einen Fehler von:
E = 1,15*0,15 kg = 0,17 kg
Mit einem Konfidenzniveau von 75%.
- Übung 5
Was ist der Grad des Vertrauens, wenn zα/2 = 2.4 ?
Lösung
P (z ≤ zα/2 ) = 1 - α/2
P (z ≤ 2.4) = 1 - α/2 = 0,9918 → α/2 = 1 - 0,9918 = 0,0082 → α = 0,0164
Der Signifikanzniveau beträgt:
α = 0,0164 = 1,64%
Und schließlich bleibt das Grad des Vertrauens:
1- α = 1 - 0,0164 = 100% - 1,64% = 98,36%
Verweise
- Canavos, g. 1988. Wahrscheinlichkeit und Statistik: Anwendungen und Methoden. McGraw Hill.
- Devore, j. 2012. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. 8. Auflage. Cengage.
- Levin, r. 1988. Statistiken für Administratoren. 2. Auflage. Prentice Hall.
- Sudman, s.1982. Fragen stellen: Ein praktischer Leitfaden zum Fragebogendesign. San Francisco. Jossey Bass.
- Walpole, r. 2007. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. Pearson.
- Wonnacott, t.H. und r.J. Wonnacott. 1990. Einführungsstatistik. 5. ed. Wiley
- Wikipedia. Beispielfehler. Abgerufen von: in.Wikipedia.com
- Wikipedia. Fehlermarge. Abgerufen von: in.Wikipedia.com
- « Inferenzstatistikgeschichte, Merkmale, wofür es, Beispiele, Beispiele
- U -Test von Mann - Whitney Was ist und wenn gilt, Ausführung, Beispiel »