

Beschreibende Statistikgeschichte, Merkmale, Beispiele, Konzepte

- 2480
- 228
- Ivan Pressler
Der Beschreibende Statistik Es ist der Zweig der Statistiken, der sich mit dem Sammeln und Organisieren von Informationen über das Verhalten von Systemen mit vielen Elementen befasst, die generell als Name von bezeichnet werden Bevölkerung.
Dafür verwendet es numerische und grafische Techniken, durch die es Informationen präsentiert, ohne Vorhersagen oder Schlussfolgerungen über die Bevölkerung zu machen, in die sie kommt.
Die beschreibenden Statistiken werden als organisiert und präsentieren die Informationen bequem [TOC]
Geschichte
Hohes Alter
Statistiken haben ihren Ursprung in der menschlichen Notwendigkeit, die notwendigen Informationen für das Überleben und das Wohlbefinden zu organisieren und die Ereignisse zu ermöglichen, die sich auf sie auswirken. Die großen Zivilisationen der Antike ließen Aufzeichnungen von Siedlern, gesammelten Steuern, Pflanzenmenge und der Größe der Armeen.
Zum Beispiel während seiner langen Regierungszeit Ramses II (1279-1213 bis.C) ordnete eine Volkszählung von Land und Einwohnern in Ägypten, die bis dahin etwa 2 Millionen Einwohner hatten.
Ebenso führte die Bibel, die Moses eine Volkszählung durchführte, um zu wissen, wie viele Soldaten die zwölf Stämme Israels hatten.
Auch im alten Griechenland wurden Menschen und Ressourcen erstellt. Die Römer, die für ihre hohe Organisation bemerkenswert sind, registrierten die Bevölkerung regelmäßig und bereiteten alle fünf Jahre Volkszählungen vor, einschließlich Gebieten und Ressourcen.
Renaissance
Nach dem Niedergang Roms waren die wichtigen statistischen Aufzeichnungen bis zur Ankunft der Renaissance, als Statistiken wieder auftauchen.
Die Wahrscheinlichkeitstheorie wurde im siebzehnten Jahrhundert gipfelte, das Ergebnis der Neigung der Menschen zum Glück.
Modernes Alter
Ein neuer Impuls kam mit der Theorie der Fehler und den Mindestquadraten im neunzehnten Jahrhundert, die der Korrelationsmethode zwischen Variablen folgten, um die Beziehung zwischen ihnen quantitativ zu bewerten.
Bis zum schließlich, während des 20. Jahrhunderts wurden die Statistiken an jeden Zweig der Wissenschaft und des Ingenieurwesens als unverzichtbares Instrument zur Problemlösung ausgedehnt.
Merkmale der beschreibenden Statistiken
Beschreibende Statistiken sind gekennzeichnet durch:
- Organisieren Sie Informationen, die in Daten und Grafiken gesammelt wurden. Die Diagramme können vielfältig sein: Histogramme, Frequenzpolygone, Kuchenhap -Diagramme unter anderem.
- Daten in Frequenzbereichen verteilen, um ihre Verwaltung zu erleichtern. Verwenden Sie die Arithmetik, um die repräsentativsten Werte der Daten durch zentrale Tendenzmaßnahmen zu finden und die Dispersion von ihnen zu analysieren.
- Bestimmen Sie die Form der Verteilungen, ihre Symmetrie, wenn sie zentriert oder voreingenommen sind und wenn sie spitz oder eher abgeflacht sind.
Kann Ihnen dienen: implizite Derivate: Wie sie gelöst und gelöst werden. ÜbungenWas ist beschreibende Statistiken für?
Wann immer es notwendig ist.
Dann erwähnen wir einige Beispiele:
Wirtschaft
Beschreibende Statistiken befassen sich mit der Registrierung und Organisation von Daten über Bevölkerungsgruppen und ihr Alter, Einkommen, Investitionen, Gewinne und Ausgaben. Auf diese Weise planen Regierungen und Institutionen Verbesserungen und investieren angemessen.
Mit Ihrer Hilfe überwachen Sie Einkäufe, Verkäufe, Renditen und Dienstleistungen Effizienz. Aus diesem Grund sind Statistiken bei der Entscheidung -das Erstellen von Entscheidungen, unverzichtbar.
Physik und mechanisch
Physik und Mechaniker verwenden Statistiken für die Untersuchung kontinuierlicher Medien, die aus einer großen Anzahl von Partikeln wie Atomen und Molekülen bestehen. Es stellt sich heraus, dass es nicht möglich ist, jeden von ihnen getrennt zu überwachen.
Untersuchen Sie jedoch das globale Verhalten des Systems (z. B. ein Gasanteil) aus makroskopischer Sicht, aber es ist möglich, Durchschnittswerte herauszufinden und makroskopische Variablen zu definieren, um seine Eigenschaften zu kennen. Ein Beispiel dafür ist die kinetische Theorie von Gasen.
Medizin
Es ist ein wesentliches Instrument bei der Überwachung von Krankheiten, aus seiner Herkunft und während seiner Entwicklung sowie der Wirksamkeit von Behandlungen.
Die Statistiken, die die Morbiditäts-, Heilungs-, Inkubationszeiten oder die Entwicklung einer Krankheit, das Alter, in dem sie normalerweise erscheint, und Stildaten beschreiben, sind bei der Gestaltung der effektivsten Behandlungen erforderlich.
Ernährung
Eine der vielen Anwendungen der deskriptiven Statistiken besteht darin, Daten über den Verbrauch von Lebensmitteln in den verschiedenen Bevölkerungsgruppen zu registrieren und zu bestellen: ihre Quantität, Qualität und die am meisten konsumierten, unter vielen anderen Beobachtungen, die Experten interessieren.
Beispiele für beschreibende Statistiken
Im Folgenden werden einige Beispiele angezeigt, die veranschaulichen, wie nützlich die Werkzeuge der beschreibenden Statistiken sind, um Entscheidungen zu treffen:
Beispiel 1
 Um die Speisesäle der Schule zu verbessern, sind Benutzerinformationen erforderlich. Quelle: Wikimedia Commons.
Um die Speisesäle der Schule zu verbessern, sind Benutzerinformationen erforderlich. Quelle: Wikimedia Commons. Die Bildungsbehörden eines Landes planen institutionelle Verbesserungen. Angenommen, sie werden ein neues System von Schulräumen implementieren.
Dafür ist es notwendig, Daten über die Studentenpopulation zu haben, beispielsweise die Anzahl der Schüler pro Klasse, Alter, Geschlecht, Größe, Gewicht und sozioökonomische Erkrankung. Dann werden diese Informationen in Form von Tabellen und Grafiken dargestellt.
Beispiel 2
Um das lokale Fußballteam zu überwachen und neue Verpflichtungen zu machen, tragen Manager die Anzahl der gespielten Spiele, gewonnen, gebunden und verloren sowie die Anzahl der Tore, Torschützen und wie sie es geschafft haben, ein Tor zu erzielen: Freistoß, vom halben Gericht, Strafen, Strafen, mit linkem Bein oder rechts unter anderem.
Es kann Ihnen dienen: gegenseitig ausschließliche Ereignisse: Eigenschaften und BeispieleBeispiel 3
Eine Eisdiele hat mehrere Geschmacksrichtungen von Eiscreme und möchte ihren Umsatz verbessern. Daher führen die Eigentümer eine Studie durch.
In dieser Studie werden zum Beispiel der Lieblingseisgeschmack und die meistverkaufte Präsentation aufgezeichnet. Und mit den gesammelten Daten planen sie die Einkäufe der Aromen und die erforderlichen Behälter und Zubehör für ihre Vorbereitung.
Grundlegende Konzepte der beschreibenden Statistiken
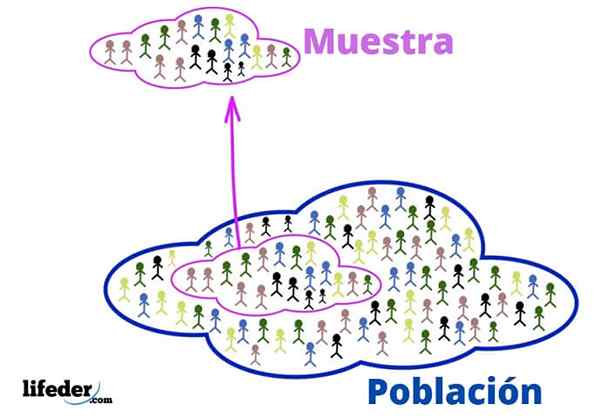 Bevölkerung und Stichprobe
Bevölkerung und Stichprobe Diese grundlegenden Konzepte sind erforderlich, um statistische Techniken anzuwenden, sehen wir:
Bevölkerung
Im statistischen Kontext bezieht sich die Bevölkerung auf das Universum oder das Kollektiv, aus dem die Informationen stammen.
Es geht nicht immer um Menschen, da sie Tiere, Pflanzen oder Objekte wie Autos, Atome, Moleküle und sogar Ereignisse und Ideen sein können.
Probe
Wenn die Bevölkerung sehr groß ist, wird eine repräsentative Stichprobe daraus extrahiert und analysiert, ohne relevante Informationen zu verlieren.
Es kann zufällig oder nach einigen Kriterien ausgewählt werden, die zuvor vom Analysten festgelegt wurden. Der Vorteil ist, dass es viel überschaubarer ist, eine Untergruppe der Bevölkerung zu sein.
Variable
Es bezieht sich auf die Wertemenge, die ein gewisses Merkmal der Bevölkerung annehmen können. Eine Studie kann verschiedene Variablen enthalten, wie Alter, Geschlecht, Gewicht, akademisches Niveau, Zivilstatus, Einkommen, Temperatur, Farbe, Zeit und vieles mehr.
Die Variablen können unterschiedlicher Natur sein, daher gibt es Kriterien, um sie zu klassifizieren und ihnen die am besten geeignete Behandlung zu geben.
Kategoriale Variablen und numerische Variablen
Gemäß der Art und Weise, wie sie gemessen werden, können die Variablen:
-Kategorisch
-Numerisch
Die kategorialen Variablen, auch genannt qualitativ, Sie repräsentieren Qualitäten wie den zivilen Status einer Person, die ledig, verheiratet, geschieden oder Witwe sein kann.
Andererseits zu numerischen Variablen oder quantitativ, Sie können gemessen werden, wie Alter, Zeit, Gewicht, Einkommen und mehr.
 Die Grafiken sind sehr wichtig, um die Informationen zu präsentieren, da der Datentrend auf einen Blick geschätzt wird. Quelle: Piqsels.
Die Grafiken sind sehr wichtig, um die Informationen zu präsentieren, da der Datentrend auf einen Blick geschätzt wird. Quelle: Piqsels. Diskrete und kontinuierliche variable Variablen
Diskrete Variablen nehmen nur diskrete Werte an, wie der Name impliziert. Beispiele dafür sind die Anzahl der Kinder einer Familie, wie viele Fächer sind in einem bestimmten Kurs und die Anzahl der Autos auf einem Parkplatz.
Diese Variablen nehmen nicht immer die gesamten Werte an, da es auch Meisterschaften gibt.
Auf der anderen Seite geben kontinuierliche Variablen unendliche Werte in einem bestimmten Bereich zu, wie das Gewicht einer Person, den pH -Wert des Blutes, die Zeit einer Telefonkonsultation und den Durchmesser der Fußballkugeln.
Kann Ihnen dienen: SymmetrieMaße der zentralen Tendenz
Geben Sie eine Vorstellung von dem allgemeinen Trend, dem die Daten folgen. Wir werden die drei am häufigsten verwendeten zentralen Maßnahmen erwähnen:
-Halb
-Median
-Mode
Halb
Entsprechen den Durchschnittswerten. Es wird berechnet, indem alle Beobachtungen hinzugefügt und zwischen der Gesamtzahl geteilt werden:

Mode
Es ist der Wert, der in einem Datensatz am häufigsten wiederholt wird, am häufigsten, da es in einer Verteilung möglicherweise mehr als eine Mode gibt.
Median
Bei der Bestellung eines Datensatzes ist der Median der zentrale Wert aller von ihnen.
Dispersionsmaßnahmen
Sie weisen auf die Variabilität der Daten hin und geben eine Vorstellung davon, wie weit oder verteilt sie aus den zentralen Maßnahmen sind. Die am häufigsten verwendeten sind:
Bereich
Es ist der Unterschied zwischen dem größten Wert xM und das kleinste xM eines Datensatzes:
Bereich = xM - XM
Varianz
Messen Sie, wie weit die Durchschnittswertdaten sind. Dafür wird ein Durchschnitt erstellt, aber mit den Unterschieden zwischen einem beliebigen Wert xYo und der durchschnittliche Quadrat, um sie daran zu hindern, sich gegenseitig zu stornieren. Es wird normalerweise durch den griechischen Buchstaben σ quadratisch oder mit s bezeichnet2:
^2N) Standardabweichung
Standardabweichung
Die Varianz hat nicht die gleichen Einheiten wie die Daten, sodass die Standardabweichung als Quadratwurzel der Varianz definiert ist und als σ oder s bezeichnet wird:
^2N) Häufigkeitsverteilungen
Häufigkeitsverteilungen
Anstatt jede Daten einzeln zu berücksichtigen, ist es vorzuziehen, sie in Bereichen zu gruppieren, was die Arbeit erleichtert, insbesondere wenn es viele Werte gibt. Zum Beispiel können sie bei der Arbeit mit den Kindern einer Schule in Altersbereiche eingeteilt werden: von 0 bis 6 Jahren, von 6 bis 12 Jahren und von 12 bis 18 Jahren.
Grafiken
Sie bieten eine hervorragende Möglichkeit, die Verteilung einer View -Daten zu schätzen und alle in den Tabellen und Bildern gesammelten Informationen enthalten, aber viel erschwinglicher.
Es gibt eine Vielzahl von ihnen: mit Balken, linearem, kreisförmigem Stamm und Blatt, Histogrammen, Frequenzpolygonen und Piktogrammen. Beispiele für statistische Graphen sind in Abbildung 3 dargestellt.
Themen von Interesse
Statistikzweige.
Statistische Variablen.
Bevölkerung und Stichprobe.
Inferenzstatistik.
Verweise
- Faraldo, p. Statistik und Forschungsmethode. Erholt von: EIO.USC.Ist.
- Fernández, s. 2002. Beschreibende Statistik. 2. Auflage. ESIC Editorial. Erholt von: Google Books.
- Statistikgeschichte. Erholt von: eumed.Netz.
- Ibañez, p. 2010. Mathematik ii. Kompetenzansatz. Cengage Lernen.
- Monroy, s. 2008. Beschreibende Statistik. 1. Auflage. Nationales Polytechnic Institute of Mexico.
- Universumformeln. Beschreibende Statistik. Erholt von: Universoumulas.com.
- « Variationskoeffizient Was ist es, Berechnung, Beispiele, Übungen
- Inferenzstatistikgeschichte, Merkmale, wofür es, Beispiele, Beispiele »