

Schätzung durch Intervalle
- 4534
- 1215
- Said Ganzmann
Was ist die Schätzung durch Intervalle?
Der Schätzung durch Intervalle Dies ist die Möglichkeit, den Wertebereich zu bestimmen, in dem der Bevölkerungsdurchschnitt einbezogen werden kann, basierend auf den Informationen einer Stichprobe der endlichen Größe, die zufällig aus der Gesamtpopulation extrahiert wird.
Er Schätzungsintervall Es ist niedriger, da die Stichprobe größer ist, aber es wird breiter, wenn der Niveau oder der Prozentsatz der Zuverlässigkeit derselben Erhöhungen erhöht.
Wenn Sie den Bevölkerungsdurchschnitt einer bestimmten Variablen in exakter Form kennen möchten, sollte die Gesamtbevölkerung berücksichtigt werden, etwas, das nicht immer machbar ist, da es teuer ist, die Daten der Daten zu erhalten, wenn es sich um eine sehr große Bevölkerung handelt gesamte Bevölkerung. Aus diesem Grund werden eine oder mehrere zufällige Stichproben der Gesamtbevölkerung verwendet, um zu nehmen.
Es basiert auf der Hypothese, dass durch Extrahieren einer zufälligen Stichprobe nicht verzerrt und unter Berücksichtigung proportionaler gesamter Schicht.
Die Logik zeigt an, dass die Differenz zwischen dem durchschnittlichen Stichprobenwert und dem durchschnittlichen Bevölkerungswert umso niedriger ist.
Schätzungsintervall
In der Praxis, sofern die vollständige Bevölkerung nicht bekannt ist, ist es nur möglich, mit gewissen Wahrscheinlichkeiten das Intervall zu finden, in dem der Bevölkerungswert gefunden werden kann, basierend auf einer Stichprobe von endlicher Größe.
Im Falle einer Bevölkerung, die einer Normalverteilung folgt, mit Standardabweichung σ , Die Standardunterschied Zwischen dem Bevölkerungsdurchschnitt μ und die durchschnittliche Größe der Größe N wird gegeben durch:
| μ - | ≤ σ / √n
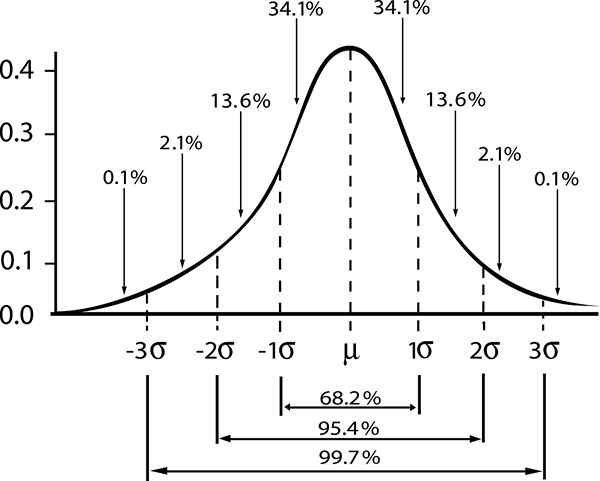
Hier gibt das Wort "Standard" an, dass 68% der Größenproben N, Sie haben einen Durchschnittswert zwischen dem Intervall [μ - σ / √n, μ + σ / √n].
Kann Ihnen dienen: Spaltbarkeitskriterien: Was sind sie, was sind die Verwendung und Regeln?Standardschätzung
Eine alternative Interpretation der oben genannten wäre zu sagen N und der Durchschnittswert wird im Intervall verstanden [ - σ / √n, + σ / √n], Mit 68% Wahrscheinlichkeit.
In den meisten realen Fällen ist es nicht möglich, die Standardbevölkerungsabweichung zu kennen, also σ Es wird durch die Standardabweichung der Probe angenähert S, das wird wie folgt berechnet:
S = √ (∑ (xYo - )2 / √ (n-1).
Von dort aus erhalten Sie das Intervall, das den Bevölkerungswert mit einem Konfidenzniveau von 68% (Standard -Konfidenzniveau) enthalten könnte, angegeben durch:
-s / √n ≤ μ ≤ + s / √n
Dieses Bevölkerungsmessintervall ist als bekannt als Standardschätzungsintervall und wurde nur mit den Daten in Größe erhalten N.
Aus der vorherigen Formel folgt, dass, wenn Sie das Schätzintervall in zwei Hälften stärken wollten, notwendig ist vervierfachen Die Größe der Probe.
Schätzung durch Konfidenzintervalle
In bestimmten Studien kann ein Standardniveau von 68% unzureichend sein, und dann müssen die Intervalle mit einem willkürlichen Konfidenzniveau bestimmen γ.
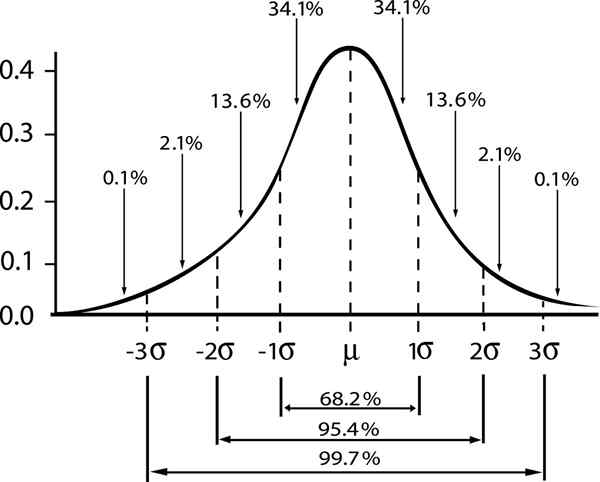 Die Beziehung zwischen der Zuverlässigkeitsspanne und dem Intervall in einer Gaußschen Verteilung wird gezeigt
Die Beziehung zwischen der Zuverlässigkeitsspanne und dem Intervall in einer Gaußschen Verteilung wird gezeigt Wenn wir bezeichnen durch ε Der Standardfehler s/√n, dann der Schätzfehler für ein Konfidenzniveau γ wird gegeben von:
E = zγ⋅ε.
Wo Zγ Es handelt sich um eine Zahl, mit der der Standardfehler multipliziert wird und somit die Fehlerquote mit einem willkürlichen Konfidenzniveau erhalten γ.
Um den Faktor zu bekommen Zγ, gehen Sie wie folgt vor:
Es kann Ihnen dienen: Rationale Zahlen: Eigenschaften, Beispiele und OperationenSchritt 1
Ist der Anruf Signifikanzniveau α entspricht dem Vertrauensniveau γ nach der folgenden Formel:
α = 1 - γ
Schritt 2
Der Wert wird bestimmt:

Schritt 3
Es klärt Zγ Die gleichung:
N (zγ) = 1 - α/2
Da es sich um eine integrale Gleichung handelt, wird diese Clearance aus den Normalverteilungstabellen unter Verwendung der linearen Interpolationsmethode erhalten.
Schritt 4
Alternativ zur Verwendung von Tabellen, die statistischen Funktionen in den Tabellenkalkulationen wie z Excel, entweder Google Sheet. Diese Programme enthalten eine normale inverse Funktion N-1, so dass der Korrekturfaktor Zγ Es wird eine direkte Bewertung dieser inversen Funktion erhalten:
Z & ggr; = n-1(1 - α/2).
Typische Vertrauensintervalle
Die am häufigsten verwendeten Konfidenzniveaus sind:
- Zγ = 1; Standard -Konfidenzniveau γ = 0,68.
- Zγ = 2; Vertrauensniveau γ = 0,95 (oder Signifikanzniveau 5%).
- Zγ = 3; Vertrauensniveau γ = 0,997 (oder 0,3%Signifikanzniveau)
Beispiele
Beispiel 1
Bestimmen Sie das durchschnittliche Gewichtsintervall von Neugeborenen im August in einer großen Stadt basierend auf einer Zufallsstichprobe von 100 Babys, bei der ein durchschnittliches Gewicht von 3100 Gramm mit einer Stichprobenstandardabweichung s = 1500 Gramm erhalten wurde.
Lösung
Zunächst wird der Standardfehler der Probe bestimmt:
ε = s/√n = (1500 g)/√100 = 150 g.
Aus dieser Stichprobe kann daher gefolgert werden, dass das durchschnittliche Gewicht der im August geborenen Babys in dieser Stadt zwischen 2950 g und 3250 g liegt, mit 68% Wahrscheinlichkeit.
Beispiel 2
Angenommen, die Größe der Stichprobe von Babys, die im selben Monat August und in derselben Stadt mit Beispiel 1 geboren wurden. Das durchschnittliche Probengewicht beträgt 3100 g mit einer Standard -Dispersion von 1500 g.
Es kann Ihnen dienen: Zersetzung natürlicher Zahlen (Beispiele und Übungen)Es wird gebeten, das durchschnittliche Gewichtsintervall der Neugeborenen dieser Stadt aus dieser neuen Stichprobe abzuschätzen.
Lösung
Jetzt verringert sich der Standardfehler in Faktor 1//√2, Der neue Standardfehler des durchschnittlichen Gewichts beträgt also 106 g.
Anschließend kann aus dieser neuen Stichprobe geschätzt werden, dass das durchschnittliche Gewicht von Neugeborenen im Bereich von 2994 g bis 3206 g mit einer Wahrscheinlichkeit von 68% besteht.
Übungen
Übung 1
Bestimmen Sie den durchschnittlichen Gewichtsbereich von Neugeborenen im August aus der in Beispiel 1 angegebenen Stichprobe mit einer Wahrscheinlichkeit von 95%.
Lösung
Ein Zuverlässigkeitsniveau von 95% verdoppelt den durchschnittlichen Gewichtsbereich im Vergleich zu einer Zuverlässigkeitsniveau von 68%.
Daher ist das durchschnittliche Gewicht von Neugeborenen im Bereich von 2800 Gramm bei 3400 Gramm mit 95% Sicherheit enthalten.
Übung 2
Schätzen Sie mit einem Konfidenzniveau von 99,7% das Intervall, in dem das durchschnittliche Gewicht von Neugeborenen aus einer großen Stadt festgestellt wird, wenn eine Probe mit einem durchschnittlichen Gewicht von 100 Babys 3100 g und einer Standardprobenabweichung s = 1500 verfügbar ist G.
Lösung
Die durchschnittliche Gewichtsfehlermarge mit 99,7% der Gewissheit verdreifacht den durchschnittlichen Fehler, das heißt:
3*1500/√100.
Aus dieser Stichprobe wird dann abgeleitet, dass das durchschnittliche Gewicht, das die Neugeborenen in das Intervall enthalten sind: 2650 Gramm bis 3550 Gramm, mit einer Gewissheit von 99,7%.
Aus diesem Ergebnis wird es beobachtet, wie mit einem größeren Maß an Sicherheit die Unsicherheit des durchschnittlichen Gewichts auf ein viel breiteres Intervall erhöht.