

Absolute Frequenzformel, Berechnung, Verteilung, Beispiel
- 4025
- 272
- Medine Kedzierski
Der Absolutes Fleiß Es ist definiert als die Häufigkeit, in der dieselben Daten im Satz von Beobachtungen einer numerischen Variablen wiederholt werden. Die Summe aller absoluten Frequenzen entspricht der Gesamtzahl der Daten.
Wenn es viele Werte einer statistischen Variablen gibt, ist es zweckmäßig, sie ordnungsgemäß zu organisieren, um Informationen über ihr Verhalten zu extrahieren. Solche Informationen werden durch zentrale Tendenzmaßnahmen und Dispersionsmaßnahmen angegeben.
Abbildung 1. Die absolute Häufigkeit einer statistischen Beobachtung ist der Schlüssel, um den Trend zu finden, der dem Datensatz folgt In den Berechnungen dieser Maßnahmen werden die Daten durch die Häufigkeit dargestellt, mit der sie in allen Beobachtungen erscheinen.
Das folgende Beispiel zeigt, wie die Erkenntnis der absoluten Häufigkeit der einzelnen Daten ist. In der ersten Maihälfte waren dies die Größen der besten Cocktailkostüme eines gut bekannten Ladies Clothing Lagers:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
Wie viele Kleider werden in einer bestimmten Größe verkauft, beispielsweise Größe 10? Die Eigentümer sind daran interessiert zu wissen, Bestellungen zu erledigen.
Die Bestellung der Daten ist leichter zu zählen. Insgesamt gibt es genau 30 Beobachtungen, als von den kleinsten bis zum höchsten so bestellt werden: sind wie folgt:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10; 10; 10; 10; 10; 10; 12; 12; 12; 12; 12; 12; 14; 14; 14; 16; 16; 18; 18
Und jetzt ist es offensichtlich, dass die Größe 10 6 -mal wiederholt wird, daher ist die absolute Frequenz gleich 6. Das gleiche Verfahren wird durchgeführt, um die absolute Frequenz der verbleibenden Größen herauszufinden.
[TOC]
Formeln
Die absolute Frequenz, bezeichnet als fYo, Es entspricht der Häufigkeit als bestimmter X -WertYo liegt innerhalb der Gruppe der Beobachtungen.
Unter der Annahme, dass die Gesamtbeobachtungen von N -Werten sind, muss die Summe aller absoluten Frequenzen der Anzahl entsprechen:
Kann Ihnen dienen: Papomudas∑fYo = f1 + F2 + F3 +… FN = N
Andere Frequenzen
Wenn jeder Wert von fYo Es ist geteilt durch die Gesamtzahl der Daten n, Sie haben die relative Frequenz FR von Wert xYo:
FR = fYo / N
Die relativen Frequenzen sind Werte zwischen 0 und 1, da n immer größer ist als alle FYo, Aber die Summe muss gleich 1 sein.
Multiplizieren Sie mit 100 zu jedem Wert von fR du hast die Relative prozentuale Häufigkeit, deren Summe 100%ist:
Relative prozentuale Frequenz = (fYo / N) x 100%
Es ist auch wichtig angesammelte Frequenz FYo Bis zu einer bestimmten Beobachtung ist dies die Summe aller absoluten Frequenzen bis zu dieser Beobachtung inklusive:
FYo = f1 + F2 + F3 +… FYo
Wenn die akkumulierte Frequenz durch die Gesamtzahl der Daten n geteilt wird, haben Sie die angesammelte relative Frequenz, Das multipliziert pro 100 führt dazu angesammelter relativer Frequenzprozentsatz.
Wie man die absolute Frequenz bekommt?
Um die absolute Häufigkeit eines bestimmten Wertes zu finden, der zu einem Datensatz gehört, sind alle von den geringsten bis zum größten organisiert und der Wert wird gezählt.
Im Beispiel der Größen der Kleider beträgt die absolute Frequenz von Größe 4 3 Kleider, das ist f1 = 3. Für Größe 6 wurden 4 Kleider verkauft: F2 = 4. In Größe 8 4 Kleider wurden auch verkauft, f3 = 4 und so weiter.
Tabellierung
Die Gesamtergebnisse können in einer Tabelle dargestellt werden, die die absoluten Frequenzen der einzelnen anzeigt:
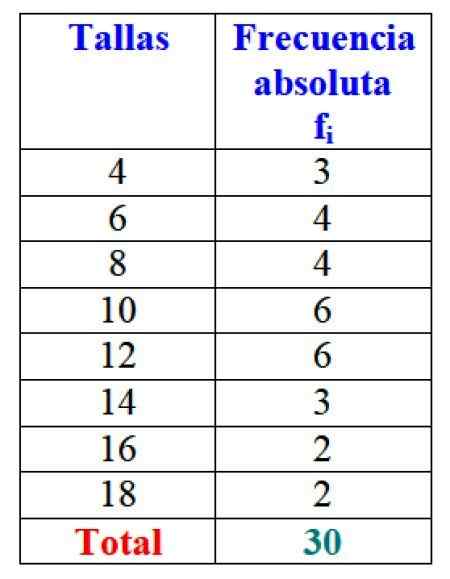 Figur 2. Tabelle, die die variable "verkaufte Verkauf" und die jeweiligen absoluten Frequenzen darstellt. Quelle: f. Zapata.
Figur 2. Tabelle, die die variable "verkaufte Verkauf" und die jeweiligen absoluten Frequenzen darstellt. Quelle: f. Zapata. Offensichtlich ist es vorteilhaft, die Informationen zu bestellen und darauf zugreifen zu können, anstatt mit losen Daten zu arbeiten.
Wichtig: Beachten Sie, dass durch Hinzufügen aller Werte von Spalte F hinzugefügt wirdYo Die Gesamtzahl der Daten wird immer erhalten. Wenn nicht, muss die Buchhaltung überprüft werden, da ein Fehler vorliegt.
Erweiterte Frequenztabelle
Die vorherige Tabelle kann erweitert werden, indem die anderen Frequenztypen in aufeinanderfolgenden Spalten rechts hinzugefügt werden:
Kann Ihnen dienen: Homozedastizität: Was ist Wichtigkeit und Beispiele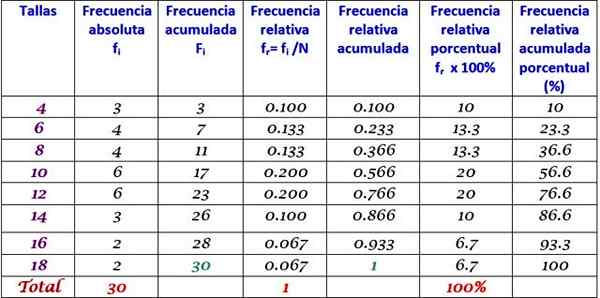
Häufigkeitsverteilung
Die Frequenzverteilung ist das Ergebnis der Organisation von Daten in Bezug auf ihre Frequenzen. Bei der Arbeit mit vielen Daten ist es zweckmäßig, sie in Kategorien, Intervalle oder Klassen zu gruppieren, jeweils mit ihren jeweiligen Frequenzen: absolut, relativ, akkumuliert und prozentual.
Das Ziel, sie zu tun.
Im Beispiel der Größen werden die Daten nicht gruppiert, da sie nicht zu viele Größen sind und leicht manipuliert und gezählt werden können. Qualitative Variablen können auch auf diese Weise bearbeitet werden, aber wenn die Daten sehr zahlreich sind, arbeiten sie besser in den Unterricht.
Frequenzverteilung für gruppierte Daten
Um die Daten in Klassen gleicher Größe zu gruppieren, muss Folgendes berücksichtigt werden:
-Größe, Breite oder Klassenamplitude: Es ist der Unterschied zwischen dem größten Wert der Klasse und dem Minderjährigen.
Die Klassengröße wird durch Aufteilung des Bereichs R durch die Anzahl der zu berücksichtigenden Klassen festgelegt. Der Bereich ist die Differenz zwischen dem Maximalwert der Daten und der Moll wie folgt:
Klassengröße = Bereich / Anzahl der Klassen.
-Klassenlimit: Intervall, das von der unteren Grenze zur Obergrenze der Klasse verläuft.
-Klassenmarke: Es ist der Mittelpunkt des Intervalls, der als repräsentativ für die Klasse angesehen wird. Es wird mit dem Semi -Limit der Obergrenze und der unteren Grenze der Klasse berechnet.
-Anzahl der Klassen: Sturges Formel kann verwendet werden:
Klassen = 1 + 3,322 log n
Wobei n die Anzahl der Klassen ist. Wie normalerweise eine Dezimalzahl ist, ist Folgendes abgerundet.
Beispiel
Eine große Fabrikmaschine ist nicht mehr in Betrieb, da sie wiederkehrende Fehler aufweist. Die aufeinanderfolgenden Inaktivitätszeiten in Minuten der Maschine werden unten mit insgesamt 100 Daten aufgezeichnet:
Es kann Ihnen dienen: Frequenzwahrscheinlichkeit: Konzept, wie es berechnet wird und Beispiele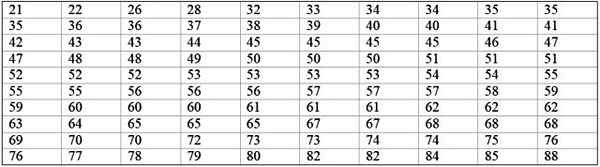
Zunächst wird die Anzahl der Klassen bestimmt:
Klassen = 1 + 3,322 log n = 1 + 3.32 log 100 = 7.64 ≈ 8
Klassengröße = Bereich / Anzahl der Klassen = (88-21) / 8 = 8.375
Es ist auch eine Dezimalzahl, daher dauert es 9 als Klassengröße.
Die Klassenmarke ist der Durchschnitt zwischen der oberen und der unteren Grenze der Klasse, beispielsweise für die Klasse [20-29). Es gibt eine Marke von:
Klasse Marke = (29 + 20) / 2 = 24.5
Fahren Sie auf die gleiche Weise fort, um die Klassenmarken der verbleibenden Intervalle zu finden.
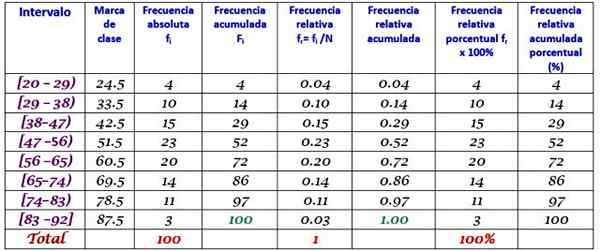
Übung gelöst
40 junge Leute gaben an, dass die Zeit in Minuten, die letzten Sonntag im Internet vergangen war, die nächste war, die zunehmend bestellt wurde:
0; 12; zwanzig; 35; 35; 38; 40; Vier fünf; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
Es wird gebeten, die Frequenzverteilung dieser Daten zu erstellen.
Lösung
Der Rang r der Datensätze von n = 40 Daten lautet:
R = 220 - 0 = 220
Die Anwendung der Sturesformel zur Bestimmung der Anzahl der Klassen ergibt das folgende Ergebnis:
Klassen = 1 + 3,322 log n = 1 + 3.32 log 40 = 6.3
Wie ein Dezimaler ist das unmittelbare Ganze 7, daher sind die Daten in 7 Klassen eingeteilt. Jede Klasse hat eine Breite von:
Klassengröße = Bereich / Anzahl der Klassen = 220/7 = 31.4
Ein enger und runder Wert beträgt 35, daher wird eine Klassenbreite von 35 gewählt.
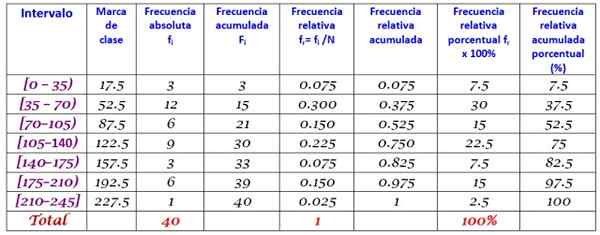
Die Klassenmarken werden berechnet, um die obere und untere Grenze jedes Intervalls zu ermitteln, z. B. für das Intervall [0,35):
Klasse Marke = (0+35)/2 = 17.5
Wir gehen auf die gleiche Weise mit den verbleibenden Klassen voran.
Schließlich werden die Frequenzen gemäß dem oben beschriebenen Verfahren berechnet, was zu der folgenden Verteilung führt:
Verweise
- Berenson, m. 1985. Statistiken für Verwaltung und Wirtschaftswissenschaften. Inter -American s.ZU.
- Devore, j. 2012. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. 8. Auflage. Cengage.
- Levin, r. 1988. Statistiken für Administratoren. 2. Auflage. Prentice Hall.
- Spiegel, m. 2009. Statistiken. Schaum -Serie. 4 Ta. Auflage. McGraw Hill.
- Walpole, r. 2007. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. Pearson.