

Positionsmaßnahmen, zentrale Tendenz und Dispersion
- 3567
- 1035
- Lewis Holzner
Der Messungen der Zentral-, Dispersions- und Positions -Tendenz, Dies sind Werte, die verwendet werden, um einen Satz statistischer Daten ordnungsgemäß zu interpretieren. Diese können direkt bearbeitet werden, wie aus der statistischen Studie erhalten oder in Gruppen gleicher Häufigkeit organisiert werden, was die Analyse erleichtert.
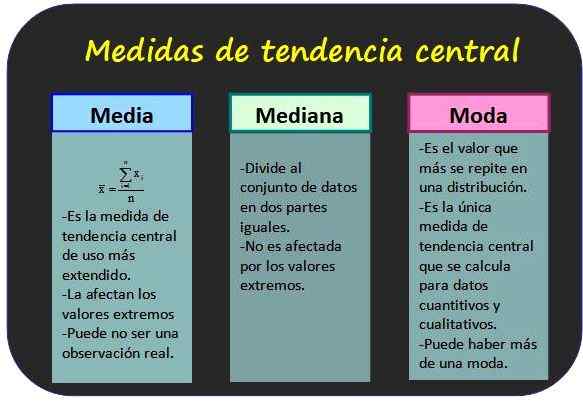
Die drei bekanntesten zentralen Trendmaßnahmen und einige seiner Eigenschaften. Quelle: f. Zapata. Maße der zentralen Tendenz
Sie lassen wissen, welche Werte die statistischen Daten zusammengefasst werden.
Arithmetischer Durchschnitt
Es ist auch als Durchschnitt der Werte einer Variablen bekannt und wird erhalten, indem alle Werte hinzugefügt und das Ergebnis durch die Gesamtzahl der Daten geteilt werden.
-
Arithmetischer Mittel für Daten ohne Gruppierung
Seien Sie eine x -Variable, von der es keine Daten ohne Organisation oder Gruppierung gibt. Der arithmetische Mittelwert wird wie folgt berechnet:

Und in summarischer Notation:

Beispiel
Die Eigentümer eines Mountain Tourist Hostel wollen wissen, wie viele Tage im Durchschnitt die Besucher in den Einrichtungen bleiben. Zu diesem Zweck wurde eine Aufzeichnung der Tage der Beständigkeit von 20 Touristengruppen durchgeführt, was die folgenden Daten erhielt:
1; 1; 2; 2; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; 2; 2; 3; 4; 1
Die durchschnittlichen Tage, an denen Touristen bleiben, sind:

-
Arithmetischer Mittel für gruppierte Daten
Wenn die variablen Daten in einer absoluten Frequenztabelle f organisiert sind FYo Und Klassenzentren sind x1, X2,…, XN, Der Durchschnitt wird berechnet durch:

In der Zusammenfassung des Sommers:

Median
Der Median einer Gruppe von n variablen X ist der zentrale Wert der Gruppe, vorausgesetzt, die Werte werden zunehmend geordnet. Auf diese Weise ist die Hälfte aller Werte niedriger als die Mode und die andere Hälfte ist größer.
-
Medium nicht gruppierter Daten
Die folgenden Fälle können vorgestellt werden:
-Zahl n Werte der Variablen x seltsam: Der Median ist der Wert, der sich nur in der Mitte der Wertegruppe befindet:

-Zahl n Werte der Variablen x Paar: In diesem Fall wird der Median als Durchschnitt der beiden zentralen Werte der Datengruppe berechnet:

Beispiel
Um den Median der touristischen Hosteldaten zu finden, werden sie zunächst am wenigsten bis zum größten bestellt:
1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 3; 3; 3; 4; 4; 4; 4; 5; 5
Es kann Ihnen dienen: Was ist die relative Frequenz und wie es berechnet wird?Die Datennummer ist ausgeglichen, daher gibt es zwei zentrale Daten: x10 und xelf Und da beide 2 wert sind, ist es auch durchschnittlich.
Median = 2
-
Medium gruppierter Daten
Die folgende Formel wird verwendet:

Die Symbole in der Formel bedeuten:
-C: Intervallbreite mit Median
-BM: Unterer Rand desselben Intervalls
-FM: Anzahl der Beobachtungen, die das Intervall enthalten, zu dem der Median gehört.
-N: Gesamtdaten.
-FBM: Anzahl der Beobachtungen vor dem Intervall, das den Median enthält.
Mode
Die Mode für nicht gruppierte Daten ist der Frequenzwert, während sie für die gruppierten Daten die Frequenzklasse ist. Es gilt als die repräsentativste Daten oder die Vertriebsklasse.
Zwei wichtige Eigenschaften dieser Maßnahme sind, dass ein Datensatz mehr als eine Mode haben kann und Mode sowohl für quantitative als auch für qualitative Daten bestimmt werden kann.
Beispiel
Wenn Sie die Daten des Touristenhostels fortsetzen, ist derjenige, der am meisten wiederholt wird. Daher ist das üblichste, dass Touristen 1 Tag im Hostel bleiben.
Dispersionsmaßnahmen
Dispersionsmaßnahmen beschreiben, wie gruppiert die Daten um die zentralen Maßnahmen gruppiert sind.
Bereich
Es wird berechnet, indem die Hauptdaten und die kleinen Daten subtrahieren. Wenn dieser Unterschied groß ist, ist dies ein Zeichen dafür, dass die Daten verteilt sind, während die kleinen Werte darauf hinweisen.
Beispiel
Der Bereich für die Touristen -Hosteldaten ist:
Bereich = 5-1 = 4
Varianz
-
Varianz für nicht gruppierte Daten
Um die Varianz zu finden s2 Es ist notwendig, zuerst den arithmetischen Durchschnitt zu kennen, dann wird die Differenz auf das Quadrat zwischen den einzelnen Daten und dem Durchschnitt berechnet, alle werden durch die Gesamtbeobachtungen zugegeben und geteilt. Diese Unterschiede sind als bekannt als Abweichungen.
^2+(x_2-\barx)^2+(x_3-\barx)^2+… (x_n-\barx)^2n)
Die Varianz, die immer positiv (oder Null) ist.
Beispiel
Die Varianz für die Daten des Touristenhostels lautet:
1; 1; 2; 2; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; 2; 2; 3; 4; 1
^2+4\times&space;(2-2.5)^2+3\times&space;(3-2.5)^2+4\times&space;(4-2.5)^2+2\times&space;(5-2.5)^220=)
-
Varianz für gruppierte Daten
Um die Varianz einer Gruppe gruppierter Daten zu ermitteln, sind sie erforderlich: i) der Durchschnitt, ii) die Frequenz fYo Welches sind die Gesamtdaten in jeder Klasse und iii) xYo oder Klassenwert:
Es kann Ihnen dienen: Arten von Dreiecken^2f_1+\left&space;(x_2-\barx&space;\right&space;)^2f_2+… +\left&space;(x_n-\barx&space;\right&space;)^2f_nn) Standardabweichung
Standardabweichung
Die Standardabweichung ist die positive Quadratwurzel der Varianz, daher hat sie einen Vorteil gegenüber der Varianz: Sie kommt in denselben Einheiten wie die untersuchte Variable und hat somit eine direktere Idee als das Schließen oder weit, was die Variable des Durchschnitts ist.
-
Standardabweichung für nicht gruppierte Daten
Es wird einfach bestimmt, indem die Quadratwurzel der Varianz für ungruitige Daten ermittelt wird:
^2+\left&space;(x_2-\barx&space;\right&space;)^2+… +\left&space;(x_n-\barx&space;\right&space;)^2n) Beispiel
Beispiel
Die Standardabweichung für touristische Hosteldaten lautet:
S = √ (s2) = √1.95 = 1.40
-
Standardabweichung für gruppierte Daten
Es wird berechnet, indem die Quadratwurzel der Varianz für gruppierte Daten ermittelt wird:
^2f_1+\left&space;(x_2-\barx&space;\right&space;)^2f_2+… +\left&space;(x_n-\barx&space;\right&space;)^2f_nn)
Positionsmaßnahmen
Positionsmessungen teilen einen geordneten Datensatz in gleiche Teile auf. Der Median ist zusätzlich zu einem zentralen Tendenzmaß auch ein Maß für die Position, da er das Ganze in zwei gleiche Teile unterteilt. Sie können jedoch kleinere Teile mit Quartilen, Dezilen und Perzentilen erhalten.
Quartile
Quartile teilen den Set in vier gleiche Teile, jeweils 25 % der Daten. Sie werden als Q bezeichnet1, Q2 und Q3 Und der Median ist das Quartil q2. Auf diese Weise liegen 25% der Daten unter dem Quartil -Q1, 50% unter dem Quartil q2 oder Median und 75% unter dem Quartil q3.
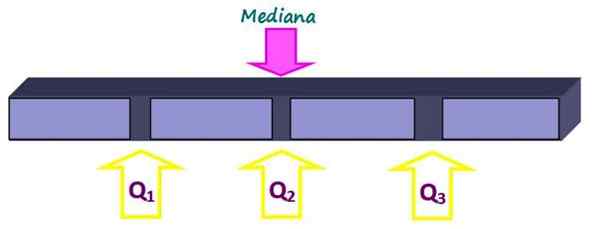 Figur 2. Quartile teilen den Datensatz in vier gleiche Teile ein. Quelle: f. Zapata.
Figur 2. Quartile teilen den Datensatz in vier gleiche Teile ein. Quelle: f. Zapata. -
Quartile für nicht gruppierte Daten
Die Daten werden geordnet und die Gesamtsumme in 4 Gruppen unterteilt, wobei die gleiche Anzahl von Daten jeweils. Die Position des ersten Quartils findet sich von:
Q1 = (n+1)/4
Die Gesamtdaten sein. Wenn das Ergebnis die gesamten Daten sind, die dieser Position entsprechen, aber wenn es dezimal ist, werden die Daten, die dem gesamten Teil mit Folgendem entsprechen.
Beispiel
Die Position des ersten Quartils Q1 Für die Daten des Touristenhostels lautet:
Q1 = (n+1) / 4 = (20+1) / 4 = 5.25
Dies ist die Position von Quartil 1, und als Ergebnis ist dezimal, werden Daten x -Daten gesucht5 und x6, die sind jeweils x5 = 1 und x6 = 1 und sie werden gemittelt, resultiert:
Erstes Quartil = 1
1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Die Position des zweiten Quartils Q2 Ist:
Kann Ihnen dienen: Teleskopsumme: Wie es gelöst wird und gelöst wirdQ2 = 2 (n+1)/4 = 10.5
Welches ist der Durchschnitt zwischen x10 und xelf und fällt mit dem Median zusammen:
Zweites Quartil = Median = 2
Die dritte Quartilposition wird berechnet durch:
Q3 = 3 (n+1) / 4 = 3 (20+1) / 4 = 15.75
Es ist auch dezimal, daher werden x gemitteltfünfzehn und x16:
1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Aber da beide 4 wert sind:
Dritter Quartil = 4
Die allgemeine Formel für die Position von Quartilen in unglücklichen Daten lautet:
Qk = K (n+1)/4
Mit k = 1,2,3.
-
Quartile für gruppierte Daten
Sie werden ähnlich wie der Median berechnet:

Die Erklärung der Symbole ist:
-BQ: unterer Rand des Intervalls, das Quartil enthält
-C: Breite dieses Intervalls
-FQ: Anzahl der Beobachtungen enthielt das Quartilintervall.
-N: Gesamtdaten.
-FBq: Anzahl der Daten vor dem Intervall, das Quartil enthält.
Deciles und Perzentile
Deciles und Perzentile teilen den Datensatz in 10 gleiche Teile bzw. 100 gleiche Teile, und ihre Berechnung wird analog zu dem von Quartilen durchgeführt.
-
Deciles und Perzentile für nicht gruppierte Daten
Formeln werden jeweils verwendet:
Dk = K (n+1)/10
Mit k = 1,2,3… 9.
Dezil d5 Es muss dem Median gleich sein.
Pk = K (n+1)/100
Mit k = 1,2,3… 99.
Das Perzentil pfünfzig Es muss dem Median gleich sein.
Beispiel
In dem Beispiel des Touristengebers der Position des d3 Ist:
D3 = 3 (20+1)/10 = 6.3
Wie ist eine Dezimalzahl gemittelt x6 und x7, beide gleich 1:
1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 3; 3; 3; 4; 4; 4; 4; 5; 5
Bedeutet, dass 3 Zehntel der Daten unter x liegen7 = 1 und die verbleibenden oben.
-
Deciles und Perzentile für gruppierte Daten
Die Formeln sind analog zu denen von Quartilen. D wird verwendet, um die Dezile und P für die Perzentile zu bezeichnen, und die Symbole werden auf ähnliche Weise interpretiert:


Die empirische Regel
Wenn die Daten symmetrisch verteilt sind und die Verteilung unimodal ist, wird eine Regel genannt Empirische Regel entweder Regel 68 - 95 - 99, Das gruppiert sie in den folgenden Intervallen:
- 68% der Daten befinden sich im Intervall:

- 95% der Daten befinden sich im Intervall:

- 99% der Daten befinden sich im Intervall:

Beispiel
In welchem Intervall sind 95% der touristischen Hosteldaten?
Sie sind im Intervall: [2.5–1.40; 2.5+1.40] = [1.1; 3.9].
Verweise
- Berenson, m. 1985. Statistiken für Verwaltung und Wirtschaftswissenschaften. Inter -American s.ZU.
- Devore, j. 2012. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. 8. Auflage. Cengage.
- Levin, r. 1988. Statistiken für Administratoren. 2. Auflage. Prentice Hall.
- Spiegel, m. 2009. Statistiken. Schaum -Serie. 4 Ta. Auflage. McGraw Hill.
- Walpole, r. 2007. Wahrscheinlichkeit und Statistik für Ingenieurwesen und Wissenschaft. Pearson.
- « Bestimmungskoeffizientenformeln, Berechnung, Interpretation, Beispiele
- Demonstration der kreisförmigen Permutationen, Beispiele, Übungen gelöst »