

Variabilitätsmaßnahmen
- 950
- 237
- Joe Hartwig
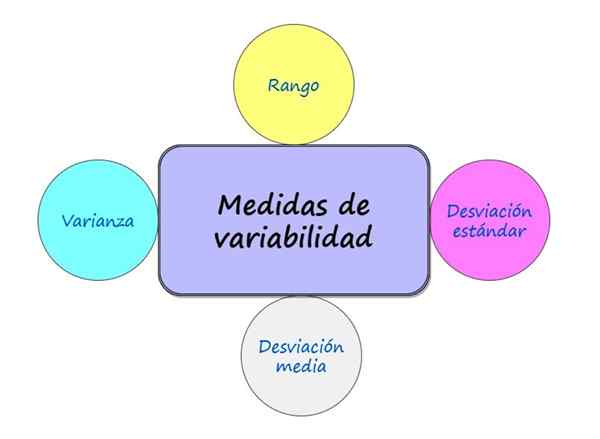
Abbildung 1.- Die bekanntesten Variabilitätsmaßnahmen. Quelle: f. Zapata. Was sind Variabilitätsmaßnahmen?
Der Variabilitätsmaßnahmen, Auch Dispersionsmaßnahmen genannt, sind sie statistische Indikatoren, die darauf hinweisen. Wenn die Daten nahe am Durchschnitt liegen, ist die Verteilung konzentriert, und wenn sie weit sind, dann ist es eine dispergierte Verteilung.
Unter den bekanntesten gibt es viele Variabilitätsmaßnahmen:
- Bereich
- Durchschnittliche Abweichung
- Varianz
- Standardabweichung
Diese Maßnahmen ergänzen die zentralen Tendenzmessungen und sind erforderlich, um die Verteilung der erhaltenen Daten zu verstehen und so viele Informationen wie möglich zu extrahieren.
Bereich
Der Bereich oder die Route misst die Amplitude eines Datensatzes. Um seinen Wert zu bestimmen, wird die Differenz zwischen dem höchsten Wert x gefundenMax und der geringste X -WertMindest:
R = xMax - XMindest
Wenn die Daten nicht locker, sondern nach Intervall gruppiert sind, wird der Bereich durch die Differenz zwischen der Obergrenze des letzten Intervalls und der unteren Grenze des ersten Intervalls berechnet.
Wenn der Bereich ein kleiner Wert ist, bedeutet dies, dass alle Daten ziemlich nahe beieinander liegen, aber ein großer Bereich zeigt an, dass es viel Variabilität gibt. Es ist offensichtlich, dass der Bereich abgesehen von der Obergrenze und der unteren Grenze der Daten die Werte zwischen ihnen nicht berücksichtigt.
Es ist jedoch eine unmittelbare Maßnahme zur Berechnung und hat dieselben Dateneinheiten, sodass es einfach ist, es zu interpretieren.
Beispiel für Rang
Als nächstes ist die Liste mit der Anzahl der am Wochenende erzielten Tore in den Fußballligen aus neun Ländern verfügbar:
Kann Ihnen dienen: Was sind die Divisors von 30?? (Erläuterung)40, 32, 35, 36, 37, 31, 37, 29, 39
Es ist ein Datensatz ohne Gruppierung. Um die Reichweite zu finden, bestellen sie sie am wenigsten bis zum größten:
29, 31, 32, 35, 36, 37, 37, 39, 40
Die Daten mit dem höchsten Wert beträgt 40 Ziele und die mit dem niedrigsten Wert beträgt 29 Ziele. Daher beträgt der Bereich:
R = 40-29 = 11 Ziele.
Es kann berücksichtigt werden, dass der Bereich im Vergleich zu den Mindestwertdaten gering ist, was 29 Ziele entspricht. Es kann also angenommen werden, dass die Daten keine große Variabilität haben.
Durchschnittliche Abweichung
Dieses Variabilitätsmaß wird im Durchschnitt der Absolutwerte der Abweichungen in Bezug auf den Durchschnitt berechnet. Die durchschnittliche Abweichung als D bezeichnetM, Für nicht gruppierte Daten wird die durchschnittliche Abweichung durch die folgende Formel berechnet:

Wobei n die Anzahl der verfügbaren Daten ist, xYo Es repräsentiert jede Daten und x̄ ist der Durchschnitt, der durch Hinzufügen aller Daten und Dividierung zwischen n: bestimmt wird:

Die durchschnittliche Abweichung ermöglicht im Durchschnitt, wie viele Einheiten die Daten vom arithmetischen Mittelwert abweichen und den Vorteil haben, die gleichen Einheiten zu haben wie die Daten, mit denen sie funktioniert.
Beispiel für mittlere Abweichungen
Nach den Daten des Bereichs beträgt die Anzahl der markierten Ziele:
40, 32, 35, 36, 37, 31, 37, 29, 39
Wenn Sie die mittlere D -Abweichung finden möchtenM Von diesen Daten ist es notwendig, zuerst den arithmetischen Mittelwert von X̄ zu berechnen:

Und jetzt, da der Wert von X̄ bekannt ist, finden wir die durchschnittliche AbweichungM:


= 2.99 ≈ 3 Ziele
Daher kann gesagt werden, dass die Daten im Durchschnitt ungefähr in drei durchschnittlichen Zielen weggehen, die 35 Ziele sind, und wie bereits erwähnt, ist dies eine viel genauere Maßnahme als der Bereich.
Kann Ihnen dienen: HyperbolaVarianz
Die durchschnittliche Abweichung ist ein viel dünneres Variabilitätsmaß als der Bereich, aber wie durch den absoluten Wert der Unterschiede zwischen den einzelnen Daten und dem Durchschnitt berechnet, bietet sie keine größere Vielseitigkeit aus dem Algebraikpunkt.
Daher wird die Varianz bevorzugt, die dem Durchschnitt der quadratischen Differenz jeder Daten mit dem Mittelwert entspricht und unter Verwendung der Formel berechnet wird:
^2n)
In diesem Ausdruck s s2 bezeichnet die Varianz und wie immer xYo Repräsentiert jedes der Daten, X̄ ist der Durchschnitt und n der Gesamtdaten.
Bei der Arbeit mit einer Stichprobe anstelle der Bevölkerung wird es vorgezogen, die Varianz wie diese zu berechnen:
^2n-1)
In jedem Fall ist die Varianz durch immer positives Betrag gekennzeichnet, aber es ist wichtig zu beobachten, dass es nicht die gleichen Einheiten hat wie die der Daten.
Beispiel für Varianz
Um die Varianz der Daten der Beispiele für Bereich und durchschnittliche Abweichung zu berechnen, werden die entsprechenden Werte ersetzt und die angegebene Summe. In diesem Fall wird es ausgewählt, sich zwischen N-1 zu teilen:
^2n-1=)
^2+\left&space;(32-35.11&space;\right&space;)^2+\left&space;(35-35.11&space;\right&space;)^2+\left&space;(36-35.11&space;\right&space;)^2+\left&space;(37-35.11&space;\right&space;)^2+\left&space;(31-35.11&space;\right&space;)^2+\left&space;(37-35.11&space;\right&space;)^2+\left&space;(29-35.11&space;\right&space;)^2+\left&space;(39-35.11&space;\right&space;)^29-1=)
= 13.86
Standardabweichung
Die Varianz hat nicht die gleiche Einheit wie die der untersuchten Variablen, beispielsweise, wenn die Daten in Messgeräten eingehen. Oder im Beispiel der Ziele wäre es in den Zielen quadratisch, was keinen Sinn ergibt.
Kann Ihnen dienen: Was sind die Elemente des Gleichnisses?? (Teile)Daher wird die Standardabweichung definiert, auch genannt Typische Abweichung, Wie die Quadratwurzel der Varianz:
S = √s2
Auf diese Weise wird ein Maß für die Variabilität der Daten in denselben Einheiten wie diese erhalten, und je niedriger der Wert von S, desto gruppierter sind die Daten um den Durchschnitt.
Sowohl die Varianz als auch die Standardabweichung sind die Variabilitätsmaßnahmen, die ausgewählt werden sollen, wenn der arithmetische Mittelwert das Maß für die zentrale Tendenz ist, die das Verhalten der Daten am besten beschreibt.
Und es ist, dass die Standardabweichung eine wichtige Eigenschaft hat, die als Chebyshevs Theorem bezeichnet wird: Mindestens 75% der Beobachtungen befinden sich in dem durch definierten Intervall durch X ± 2s. Mit anderen Worten, 75% der Daten sind höchsten.
Ebenso liegen mindestens 89% der Werte in einer Entfernung von 3 Sekunden vom Durchschnitt, einem Prozentsatz, der erweitert werden kann, vorausgesetzt, dass viele Daten verfügbar sind und diese einer Normalverteilung folgen.
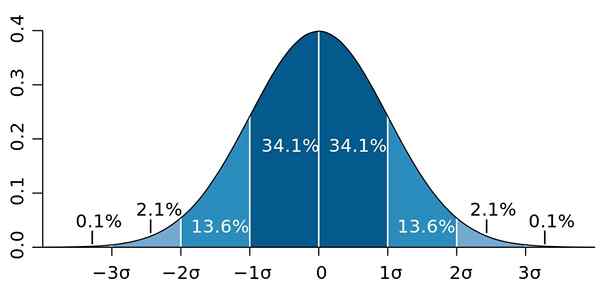
Figur 2.- Wenn die Daten einer Normalverteilung folgen, 95.4 von ihnen sind zwei Standardabweichungen auf beiden Seiten des Durchschnitts. Quelle: Wikimedia Commons.
Beispiel für die Standardabweichung
Die Standardabweichung der in den vorherigen Beispielen dargestellten Daten ist:
S = √s2 = √13.86 = 3.7 ≈ 4 Tore
- « Verteilung F Eigenschaften und Übungen gelöst
- Quoten -Stichprobenmethode, Vor-, Nachteile, Beispiele »