

Zufällige Stichprobenmethodik, Vorteile, Nachteile, Beispiele

- 1500
- 83
- Rieke Scheer
Er Stichproben Dies ist die Möglichkeit, eine statistisch repräsentative Stichprobe aus einer bestimmten Population auszuwählen. Teil des Prinzips, dass jedes Element der Stichprobe die gleiche Wahrscheinlichkeit haben muss, ausgewählt zu werden.
Eine Verlosung ist ein Beispiel für eine zufällige Stichprobe, bei der jedem Mitglied der Bevölkerung der Teilnehmer eine Nummer zugewiesen wird. Um die Zahlen auszuwählen, die den Verlosungspreisen (der Probe) entsprechen, wird eine zufällige Technik verwendet, z.
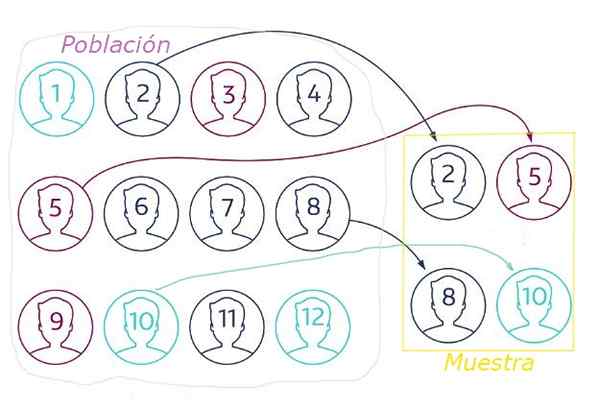 Abbildung 1. Bei der zufälligen Stichprobe wird die Stichprobe durch eine Technik aus der zufälligen Population extrahiert, die sicherstellt, dass alle Elemente die gleiche Wahrscheinlichkeit haben, ausgewählt zu werden. Quelle: Netquest.com.
Abbildung 1. Bei der zufälligen Stichprobe wird die Stichprobe durch eine Technik aus der zufälligen Population extrahiert, die sicherstellt, dass alle Elemente die gleiche Wahrscheinlichkeit haben, ausgewählt zu werden. Quelle: Netquest.com. Bei zufälliger Stichproben ist es unerlässlich.
[TOC]
Die Größe der Probe
Es gibt Formeln, um die richtige Größe einer Probe zu bestimmen. Der wichtigste Faktor ist zu berücksichtigen, ob die Bevölkerungsgröße bekannt ist oder nicht. Schauen wir uns die Formeln an, um die Stichprobengröße zu bestimmen:
Fall 1: Die Bevölkerungsgröße ist nicht bekannt
Wenn die Größe der Bevölkerung unbekannt ist, ist es möglich, eine angemessene N -Stichprobe auszuwählen, um festzustellen, ob eine bestimmte Hypothese wahr oder falsch ist.
Zu diesem Zweck wird die folgende Formel verwendet:
n = (z)2 P q)/(e2)
Wo:
-P Es ist die Wahrscheinlichkeit, dass die Hypothese wahr ist.
-Q ist die Wahrscheinlichkeit, dass es nicht ist, daher q = 1 - p.
-E ist die relative Fehlerquote, beispielsweise hat ein 5% -Fehler eine Marge E = 0,05.
-Z hat mit dem von der Studie erforderlichen Vertrauensniveau zu tun.
Kann Ihnen dienen: Normalverteilung: Formel, Eigenschaften, Beispiel, ÜbungIn einer normalen (oder normalisierten) Normalverteilung hat ein Konfidenzniveau von 90% z = 1.645, da die Wahrscheinlichkeit, dass das Ergebnis zwischen -1,645σ und +1.645σ liegt, 90% beträgt, wobei σ die Standardabweichung ist.
Vertrauensniveaus und ihre entsprechenden Zwerte
1.- 50% Konfidenzniveau entspricht Z = 0,675.
2.- 68.3% Konfidenzniveau entspricht Z = 1.
3.- 90% Konfidenzniveau entspricht Z = 1.645.
4.- 95% Konfidenzniveau entspricht Z = 1,96
5.- 95,5% Konfidenzniveau entspricht Z = 2.
6.- 99,7% Konfidenzniveau entspricht Z = 3.
Ein Beispiel, bei dem diese Formel angewendet werden kann, wäre in einer Studie, um das durchschnittliche Gewicht der Kieselsteine eines Strandes zu bestimmen.
Es ist eindeutig nicht möglich, alle Kieselsteine des Strandes zu studieren und zu wiegen, daher ist es bequem.
 Figur 2. Um die Eigenschaften der Kieselsteine eines Strandes zu untersuchen. (Quelle: Pixabay)
Figur 2. Um die Eigenschaften der Kieselsteine eines Strandes zu untersuchen. (Quelle: Pixabay) Fall 2: Bevölkerungsgröße ist bekannt
Wenn die Zahl n von Elementen, aus denen eine bestimmte Population (oder Universum) besteht, bekannt ist, wenn Sie durch einfache zufällige Stichprobe eine statistisch signifikante Stichprobe auswählen möchten, ist dies die Formel:
n = (z)2p q n)/(n e2 + Z2P q)
Wo:
-Z ist der Koeffizient, der mit dem Vertrauensniveau verbunden ist.
-P ist die Wahrscheinlichkeit des Erfolgs der Hypothese.
-Q ist die Wahrscheinlichkeit eines Versagens in der Hypothese, p + q = 1.
-N ist die Größe der Gesamtbevölkerung.
-E ist der relative Fehler des Studienergebnisses.
Beispiele
Die Methodik zum Extrahieren der Proben hängt stark von der Art der Studie ab, die erforderlich ist. Daher hat zufällige Stichproben unzählige Anwendungen:
Kann Ihnen dienen: Zeichen der GruppierungUmfragen und Fragebögen
Zum Beispiel werden in Telefonumfragen die Personen ausgewählt, um von einem zufälligen Zahlengenerator konsultiert zu werden, der für die untersuchte Region anwendbar ist.
Wenn Sie einen Fragebogen an die Mitarbeiter eines großen Unternehmens anwenden möchten, kann die Auswahl der Befragten über ihre Mitarbeiternummer oder Identitätskartennummer verwendet werden.
Diese Zahl muss auch zufällig ausgewählt werden, z. B. unter Verwendung eines Zufallszahlengenerators.
Figur 3. Ein Fragebogen kann zufällig die Teilnehmer auswählen. Quelle: Pixabay. QA
Für den Fall, dass sich die Studie an den von einer Maschine hergestellten Teilen befindet, müssen Teile zufällig ausgewählt werden, aber von Grundstücken zu verschiedenen Tageszeit.
Vorteile
Einfache zufällige Stichprobe:
- Es ermöglicht es, die Kosten einer statistischen Studie zu senken, da es nicht erforderlich ist, die Gesamtpopulation zu untersuchen, um statistisch zuverlässige Ergebnisse zu erhalten, wobei das gewünschte Vertrauensniveau und das in der Studie erforderliche Fehlerniveau erforderlich sind.
- Vermeiden Sie Verzerrungen: Da die Auswahl der zu untersuchenden Elemente vollständig zufällig ist, spiegelt die Studie die Merkmale der Bevölkerung treu wider, obwohl nur ein Teil desselben untersucht wurde.
Nachteile
- Die Methode ist in Fällen nicht angemessen, in denen Sie die Vorlieben in verschiedenen Gruppen oder Bevölkerungsschichten kennenlernen möchten.
In diesem Fall ist es vorzuziehen, zuvor die Gruppen oder Segmente zu bestimmen, zu denen die Studie durchgeführt wird. Sobald die Schichten oder Gruppen definiert wurden.
- Es ist sehr unwahrscheinlich, dass Informationen über die Minderheitensektoren erhalten werden, von denen es manchmal notwendig ist, ihre Merkmale zu kennen.
Kann Ihnen dienen: Simpson -Regel: Formel, Demonstration, Beispiele, ÜbungenWenn es sich beispielsweise um eine Kampagne für ein teures Produkt handelt, ist es notwendig, die Vorlieben der reichsten Minderheitensektoren zu kennen.
Übung gelöst
Wir wollen die Präferenz der Bevölkerung durch die Cola von Cola untersuchen, aber es gibt keine frühere Studie in dieser Bevölkerung, von der seine Größe unbekannt ist.
Andererseits muss die Stichprobe mit einem Mindestkonfidenzniveau von 90% repräsentativ sein, und die Schlussfolgerungen müssen einen prozentualen Fehler von 2% aufweisen.
-So bestimmen Sie die S -Größe der Probe?
-Wie groß wäre die Stichprobengröße, wenn die Fehlerquote bis zu 5% bestehen würde?
Lösung
Da die Populationsgröße unbekannt ist, wird die oben angegebene Formel verwendet, um die Größe der Stichprobe zu bestimmen:
n = (z)2P q)/(e2)
Wir gehen davon aus, dass die gleiche Präferenzwahrscheinlichkeit (p) durch unsere Erfrischung der Nicht -Preferenz (q) und dann p = q = 0,5 besteht.
Andererseits muss der relative Fehler 0,02 beträgt, da das Studienergebnis einen prozentualen Fehler von weniger als 2%aufweisen muss.
Schließlich erzeugt ein Wert Z = 1.645 ein Konfidenzniveau von 90%.
Kurz gesagt, Sie haben die folgenden Werte:
Z = 1.645
P = 0,5
Q = 0,5
E = 0,02
Mit diesen Daten wird die minimale Stichprobengröße berechnet:
N = (1.6452 0,5 0,5)/(0,02)2) = 1691.3
Dies bedeutet, dass die Studie mit dem erforderlichen Fehlerrand und mit dem gewählten Vertrauensniveau über eine Stichprobe von Befragten von mindestens 1692 Personen verfügen.
Wenn Sie von einer Fehlerspanne von 2% bis 5% ausgehen, lautet die neue Stichprobengröße:
N = (1.6452 0,5 0,5)/(0,05)2) = 271
Dies ist eine deutlich geringere Anzahl von Personen. Zusammenfassend ist die Stichprobengröße sehr empfindlich gegenüber dem gewünschten Rand in der Studie.
Verweise
- Berenson, m. 1985.Statistiken für Verwaltung und Wirtschaft, Konzepte und Anwendungen. Inter -American Editorial.
- Statistiken. Stichproben. Entnommen aus: Enzyklopädie -Ökonomika.com.
- Statistiken. Probenahme. Erholt aus: Statistik.Matte.USON.mx.
- Erkundig. Stichproben. Erholt von: explorierbar.com.
- Moore, d. 2005. Grundlegende Statistiken angewendet. 2. Auflage.
- Netquest. Stichproben. Erholt von: Netquest.com.
- Wikipedia. Statistische Stichprobe. Abgerufen von: in.Wikipedia.Org